
Sample-based Learning Methods - 01. Week 1. Monte Carlo Methods for Prediction & Control
관련 자료 (RLbook2018 Pages 91-104)
- Monte Carlo Methods
- 개요
- 이번 챕터에서는 환경에 대한 완전한 지식을 가정하지 않는다.
- 몬테 카를로 방식은 경험만을 필요로 한다.
- 환경과의 실제 혹은 가상의 상호작용을 통한 샘플 시퀀스 (상태, 행동, 보상)
- 실제 경험을 통해 배우는 것은 엄청난 이점인데, 환경 역학에 대한 선행 지식 없이 최적 행동을 얻을 수 있기 때문이다.
- 가상 경험을 통해 배우는 것도 마찬가지이다.
- 비록 모델이 필요하지만, 모델은 오직 샘플 전환만을 생성하면 되고, DP 처럼 모든 가능한 전환의 완전한 확률 분포가 필요한 것은 아니다.
- 많은 경우 원하는 확률 분포에 따라 샘플링된 경험을 생성하는 것은 쉽지만, 명시적인 형태로 분포를 얻는 것은 불가능하다.
- Monte Carlo Methods
- 몬테카를로 방식은 강화학습 문제를 샘플링된 리턴 값의 평균 기반으로 해결하는 방식이다.
- 잘 정의된 리턴 값이 가능하도록, 우리는 몬테카를로 방식을 episodic tasks 에만 정의한다.
- 각 경험은 에피소드 단위로 나눈다.
- 모든 에피소드는 어떠한 행동을 선택하더라도 필연적으로 종료된다.
- 에피소드 완료 시에만 가치 추정 및 정책이 변경된다.
- 따라서 몬테카를로 방식은 에피소드 별로 증분이 된다.
- step-by-step (online) 방식은 아니다.
- 잘 정의된 리턴 값이 가능하도록, 우리는 몬테카를로 방식을 episodic tasks 에만 정의한다.
- 몬테카를로 라는 용어는 작업에 상당한 무작위 요소가 포함된 추정 방법에 광범위하게 사용되는 경우가 많다.
- 여기에서 우리는 전체 수익의 평균을 기반으로 하는 방법에 대하여 몬테카를로 방식이라 한다.
- 추후 학습할 부분 수익으로 학습하는 방법과 반대
- 몬테카를로 방식은 강화학습 문제를 샘플링된 리턴 값의 평균 기반으로 해결하는 방식이다.
- 몬테카를로 방식과 Bandit 방식
- 몬테카를로 방식은 강화학습에서 상태-행동 쌍마다 샘플링하고 평균 반환값을 계산한다.
- 이는 2장에서 다룬 밴딧 방법과 유사하게 각 행동에 대한 샘플링과 평균 보상을 계산하는 것임.
- 차이점은 몬테카를로 방식에서는 여러 상태가 있고, 각각이 다른 밴딧 문제와 유사하게 작동하며, 각 문제들은 상호 관련되어 있다는 점이다.
- 즉, 하나의 상태에서 행동을 수행한 후, 이후 상태에서 수행한 행동에 따라 반환값이 영향을 받음.
- 모든 행동선택이 학습을 진행하고 있는 중이기에 이전 상태의 관점에선 비정상성 (nonstationary) 의 변화하는 문제가 됨.
- 몬테카를로 방식은 강화학습에서 상태-행동 쌍마다 샘플링하고 평균 반환값을 계산한다.
- 몬테카를로 방식과 GPI (Generalized Policy Iteration)
- 비정상성 (nonstationary) 를 해결하기 위해, GPI 의 아이디어를 적용한다.
- 기존 GPI 에선 MDP 의 사전지식을 통해 가치함수를 계산했다면, 여기서는 MDP 에서 주는 샘플 리턴값을 통해 가치함수를 학습한다.
- 가치함수와 상응하는 정책은 여전히 최적성을 얻기 위해 본질적으로 같은 방법 (GPI) 으로 상호작용한다.
- GPI 에서 했던 동일한 과정으로, 몬테카를로 케이스의 경우 (경험만 샘플링 가능한 상황) 에도 적용한다.
- Prediction Problem
- Policy Improvement
- Control Problem
- 비정상성 (nonstationary) 를 해결하기 위해, GPI 의 아이디어를 적용한다.
- 개요
- Monte Carlo Prediction
- 개요
- 우리는 시작으로, 몬테카를로 방식을 이용한 주어진 정책의 상태가치함수의 학습을 고려해 볼 것이다.
- 상태의 값은 예상되는 리턴 값 (미래의 할인된 기대 보상 합) 임을 상기한다.
- 단순히 해당 상태에 방문하고, 리턴값을 관찰하는 것이 경험을 통해 측정하는 명백한 방법이다.
- 더 많은 리턴 값이 관측되면, 평균은 반드시 예측 값에 수렴한다.
- 위의 아이디어가 몬테카를로 방식의 기반이 된다.
- 몬테카를로 예측
- 우리가 특별히 $v_\pi (s)$ 를 예측, 즉 정책 $\pi$ 아래의 s 상태의 값을 $\pi$ 정책을 따르고, s 상태를 지나는 에피소드 셋을 통해 예측한다고 가정
- 에피소드 내에서 각각의 상태 s 에 발생하는 것을 s 에 방문한다 (visit to s) 라 한다.
- s 는 같은 에피소드 내에서도 여러 번 방문될 수 있다.
- 첫 방문을 first visit to s 라 칭하도록 한다.
- 몬테카를로 방식 (MC method) 을 나누는 기준
- every-visit MC method
- s 를 방문할 때마다의 리턴 값의 평균을 구한다.
- 함수 근사 (function approximation) 와 적격성 추적 (eligibility traces) 확장에 더 자연스럽다.
- 나중에 (Chapter 9, 12) 다룰 방식
- 아래 first-visit 방식에서 $S_t$ 가 에피소드 초반에 일어났는지 체크하는 부분을 제외하고 동일하다.

- first-visit MC method
- s 의 첫 방문의 리턴 값의 평균을 구한다.
- 1940년대 부터 가장 많이 연구 되는 방식
- 이 장에서 다룰 방식
- Termination 상태부터 할인된 보상합을 계산하되, 이 값이 $S_t$ 가 되면 이전 에피소드 보상합에 포함시켜 평균을 구한다.
- first-visit MC 와 every-visit MC 모두 $s$ 상태에 대한 방문 (혹은 첫 방문) 의 수가 무한대에 가까워질 경우 $v_\pi (s)$ 로 수렴한다.
- first-visit MC 의 경우
- 각 리턴 값은 유한한 분산을 가진 $v_\pi (s)$ 의 독립적이고 동일하게 분포된 추정치이다.
- 대수의 법칙에 따라 이러한 추정치의 평균 시퀀스는 기대값으로 수렴한다.
- 각 평균은 그 자체로 편향되지 않은 추정치이며, 그 오차의 표준 편차는 $\frac{1}{\sqrt{n}}$ 으로 감소한다.
- n 은 평균을 구한 반환값의 개수이다.
- every-visit MC 는 덜 직관적이지만, 그 추정치 또한 $v_\pi (s)$ 로 2차 수렴한다. (Singh and Sutton, 1996)
- every-visit MC method
- Example 5.1 : Blackjack
- 게임의 설명
- 블랙잭이라는 대중적인 카지노 카드 게임의 목적은 수치의 합이 21을 초과하지 않고 가능한 한 큰 카드를 얻는 것
- 모든 FACE 카드는 10으로 계산되며 에이스는 1 또는 11로 계산될 수 있습니다.
- 각 플레이어가 딜러와 독립적으로 경쟁하는 버전을 고려함.
- 게임은 딜러와 플레이어 모두에게 두 장의 카드를 나눠주는 것으로 시작됨.
- 딜러의 카드 중 하나는 위를 향하고 다른 하나는 아래를 향함.
- 플레이어가 즉시 21개(에이스와 10장의 카드)를 가지고 있으면 이를 내추럴이라고 함.
- 딜러도 내추럴을 가지고 있지 않는 한 플레이어가 이기며, 가지고 있을 경우 게임은 무승부가 됨.
- 플레이어가 내츄럴 카드를 가지고 있지 않다면, 21을 초과 (bust) 하지 않는 선에서, 추가 카드 한장을 요청 (hits) 하거나 멈출 (sticks) 수 있음.
- 21을 초과 (bust) 하면 패배
- 멈추면 (sticks) 딜러의 턴이 됨.
- 딜러는 선택의 여지 없이 고정된 전략에 따라 히트하거나 스틱함. 그는 17 이상의 합계이면 스틱하고, 그렇지 않으면 히트함.
- 딜러가 21을 초과 (bust) 하면 플레이어가 승리함.
- 그렇지 않은 경우 결과 (승리, 무승부) 는 최종 합이 21에 가까운 사람이 승리함.
- MDP 정의
- 블랙잭을 플레이하는 것은 자연스럽게 일시적인 유한 MDP로 공식화됨.
- 각 게임은 에피소드
- 보상은 승리, 패배, 무승부에 따라 각각 +1, -1 또는 0 이 주어짐.
- 이 종료 보상은 수익이기도 함.
- 게임 내의 모든 보상은 0. 보상 할인은 사용하지 않음 ($\gamma = 1$)
- 플레이어의 행동은 힛 또는 스틱임.
- 상태는 플레이어의 카드와 딜러의 표시 카드임.
- 이미 처리된 카드를 카운팅하는 이점이 없도록 무한한 덱 (교체 포함) 에서 카드가 처리된다고 가정함.
- 플레이어가 버스트되지 않고 11로 셀 수 있는 에이스를 보유하고 있으면 그 에이스는 사용 가능하다고 한다.
- 이 경우 1로 계산하면 합계가 11 이하가 되기 때문에 항상 11로 계산됨.
- 1로 계산하는 경우 플레이어는 항상 힛을 해야 하기 때문에 결정을 내릴 수 없음.
- 힛을 했을 때 버스트 되는 경우 에이스를 1로 계산할 수 있음.
- 따라서 플레이어는 자신의 현재 합계(12–21), 딜러가 보여주는 카드(ace–10), 사용 가능한 에이스 보유 여부의 세 가지 변수를 기반으로 결정을 내림.
- 이렇게 하면 총 200개의 상태가 됨.
- 정책의 설정
- 플레이어의 합계가 20 또는 21이면 스틱, 그렇지 않으면 힛을 하는 정책을 고려한다.
- 몬테카를로 접근방식으로 이 정책에 대한 상태가치함수를 찾기 위해, 해당 정책으로 많은 블랙잭 게임을 시뮬레이션하고 각 상태에 따른 수익을 평균화함.
- 사용 가능한 에이스가 있는 상태에 대한 추정치는 이러한 상태가 덜 일반적이기 때문에 덜 확실하고 덜 규칙적임.
- 어쨌든 500,000 게임 후에 가치 함수는 매우 잘 근사됨.
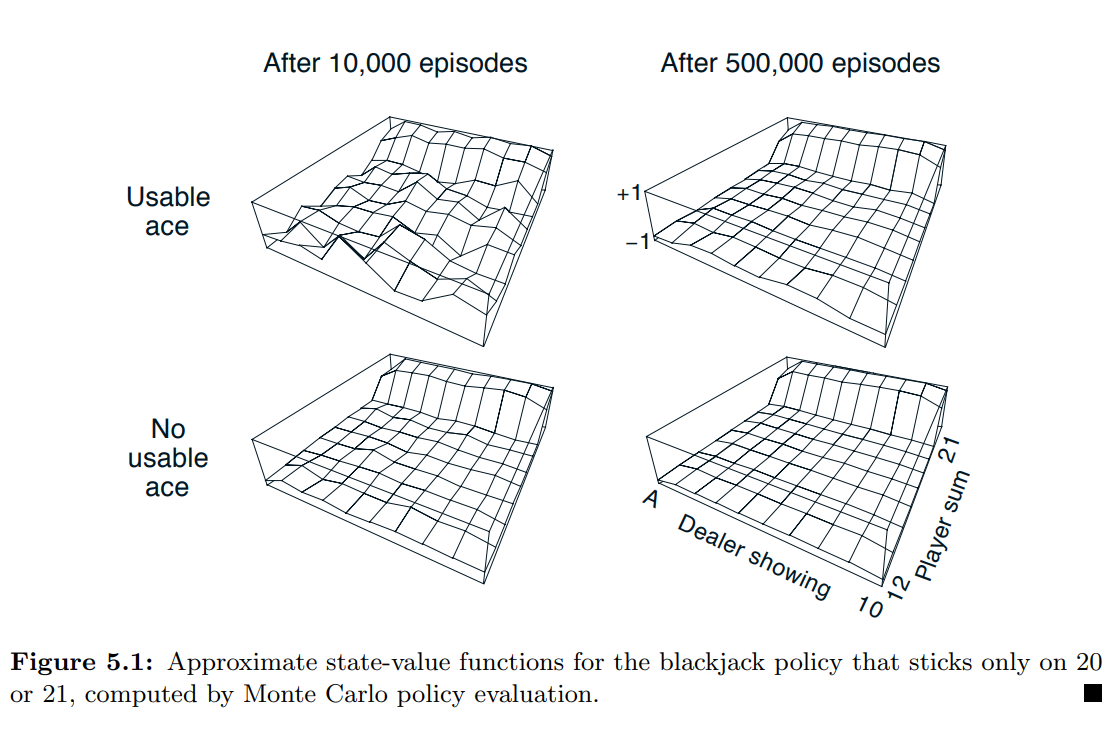
- 게임의 설명
- DP 와 비교한 몬테카를로의 장점
- 위의 블랙잭 게임에서 우리는 환경에 대한 완벽한 지식을 갖고 있지만, DP 를 사용하여 가치함수를 계산하는 것은 쉽지 않은 문제이다.
- DP 방식의 경우 다음 이벤트의 분포를 필요 (특히, 4개의 인수를 가지는 환경역학 $p(s’,r | s,a)$)
- 블랙잭에 대해 이를 결정하는 것이 쉽지 않음.
- 예를 들어 플레이어의 합이 14이고, 힛을 선택하는 경우 딜러의 공개 카드에 따른 보상이 +1 이 되는 확률
- DP를 적용하기 위해서는 모든 확률을 계산해야 하며, 이러한 계산은 종종 복잡하고 오류가 발생할 수 있음.
- 반면에, 몬테카를로 방식에서 필요한 샘플 게임을 생성하는 것은 쉽다.
- 샘플 에피소드만으로 작업하는 몬테카를로 방법이 환경 역학에 완전한 지식을 갖고 있는 경우에도 상당한 장점이 될 수 있다.
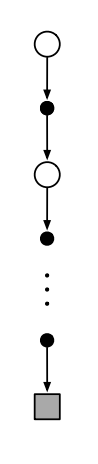
- 몬테카를로에서는 백업 다이어그램의 개념을 사용할 수 없음.
- 백업 다이어그램 : 업데이트될 루트 노드를 상단에 표시하고, 업데이트에 기여하는 보상, 예측값을 가진 모든 전이, 리프 노드를 아래에 표기
- $v_\pi$ 의 몬테카를로 추정의 경우 루트는 상태노드이고, 그 아래에 최종 상태로 끝나는 특정 단일 에피소드의 전체 전이 궤적이 있다.
- DP 다이어그램은 가능한 모든 전이를 보여주는 반면, 몬테카를로 다이어그램은 하나의 에피소드에서 샘플링된 전이만을 보여줌.
- DP 다이어그램은 한 단계 전이만 포함하지만, 몬테카를로 다이어그램은 에피소드의 끝까지 이어짐.
- 몬테카를로 방식의 중요한 사실은 각 상태의 추정치가 서로 독립적이라는 것임.
- 현 상태의 추정치는 다른 상태에 의존하지 않음. (DP에서 정의한 부트스트랩 방식을 사용하지 않음.)
- 하나의 상태의 값을 추정하는 계산 비용은 상태의 수와 독립적임.
- 즉, 몬테카를로 방식은 하나 또는 일부의 상태의 값만 필요한 경우 특히 유리함.
- 위의 블랙잭 게임에서 우리는 환경에 대한 완벽한 지식을 갖고 있지만, DP 를 사용하여 가치함수를 계산하는 것은 쉽지 않은 문제이다.
- 개요
-
Monte Carlo Estimation of Action Values
- 모델이 없을 경우에서의 몬테카를로 방식
- 모델을 사용할 수 없는 경우, 상태 값이 아닌 행동 값 (상태-행동 쌍) 을 추정하는 것이 특히 유용함.
- 모델이 있는 경우, 상태 값만으로 정책을 결정하기 충분함.
- DP 에 대해 다룰 때, 단순히 한 단계 앞을 보고, 보상과 다음 상태의 최상의 조합으로 이어지는 행동을 선택하면 됐었음.
- 그러나 모델이 없을 경우, 상태값만으로 충분하지 않음.
- 정책을 제안하는 데 유용하게 사용하기 위해 각 행동의 가치를 명시적으로 추정해야 함.
- 따라서 몬테카를로 방법의 주요 목표 중 하나는 $q_*$ 를 추정하는 것임.
- 모델이 있는 경우, 상태 값만으로 정책을 결정하기 충분함.
- 모델을 사용할 수 없는 경우, 상태 값이 아닌 행동 값 (상태-행동 쌍) 을 추정하는 것이 특히 유용함.
- 행동 값에 대한 정책 평가 문제를 고려하기
- 상태 $s$ 에서 시작하여 행동 $a$ 를 취한 후 정책 $\pi$ 를 따를 때 기대되는 보상인 $q_\pi (s,a)$ 를 추정하는 것.
- 이를 위한 몬테카를로 방법은 위의 상태가치함수를 구하는 것과 본질적으로 동일하나 이제 상태가 아닌 상태-행동 쌍에 대한 방문에 대해 이야기함.
- 상태-행동 쌍, $s,a$ 는 상태 $s$ 에서 행동 $a$ 를 취할 때 에피소드 내에서 방문했다 (visited) 라고 표현함.
- every-visit MC 의 경우 모든 방문에 따른 리턴 값의 평균으로 상태-행동 쌍의 값을 추정함.
- first-visit MC 의 경우 각 에피소드 내에서 처음으로 상태 $s$ 에 방문하고 행동 $a$ 를 취한 리턴 값의 평균을 구함.
- 이러한 방법은 방문 횟수가 무한대로 접근할 때 이전과 같이 2차적으로 수렴함. (변화가 점점 안정화 되는 패턴)
- 유일한 복잡성은 많은 상태-행동 쌍이 방문되지 않을 수도 있다는 점임.
- $\pi$ 가 결정론적 정책인 경우, $\pi$ 를 따를 때, 각 상태에서는 행동 중 하나에 대한 리턴값만 관찰하게 될 것임.
- 평균화할 리턴값이 없으므로, 다른 행동들의 몬테카를로 추정은 경험을 통해 개선되지 않을 것임.
- 행동 값을 학습하는 목적이 각 상태에서 사용할 수 있는 행동 중에서의 선택을 돕는 것이기 때문에 이것은 심각한 문제임.
- 행동의 대안을 비교하려면 현재 선호하는 것 뿐만 아니라 각 상태의 모든 행동의 가치를 추정해야 한다.
- 이것은 2장의 k-armed bandit 문제의 맥락에서 논의된 탐색 유지 문제의 일반적인 문제이다.
- 지속적인 탐색의 보장
- 행동 값에 대한 정책 팽가(policy evaluation) 를 위해서는 모든 상태-행동 쌍이 방문되는 것을 보장해야 함.
- 이를 위한 한 가지 방법은 에피소드가 상태-행동 쌍에서 시작되도록 지정하고, 모든 쌍이 시작점으로 선택될 확률이 0이 아니게 하는 것이다.
- 이렇게 하면 모든 상태-행동 쌍이 에피소드의 무한한 횟수에 따라 방문되도록 보장됨.
- 이를 탐색 시작 가정 (assumption of exploring starts) 이라 한다.
- 탐색 시작 가정은 때때로 유용하나, 일반적으로, 특히 환경과의 실제 상호 작용에서 직접 학습할 때에는 의존할 수 없게 된다.
- 이 경우, 시작 조건이 도움이 되지 않음.
- 모든 상태-행동 쌍이 발생하도록 보장하는 가장 일반적인 대안 접근 방식은 각 상태에서 모든 행동을 선택할 확률이 0이 아닌 확률로, 확률론적 정책만 고려하는 것이다.
- 이후 섹션에서 이 접근 방식의 두 가지 중요한 변형에 대해 설명할 것이나, 지금은 탐색 시작 가정을 유지한 전체 몬테카를로 제어 방법을 소개한다.
- 모델이 없을 경우에서의 몬테카를로 방식
- Monte Carlo Control
- 몬테카를로 제어(Control) 와 GPI (Generalized Policy Iteration)
- 몬테카를로 추정 (Monte Carlo estimation) 이 제어, 즉 최적의 정책에 근접하는 데 어떻게 사용될 수 있는지 고려해보자.
- 전반적인 아이디어는 동적프로그래밍(DP) 와 동일한 패턴, 즉 일반화된 정책 반복(GPI:Generalized Policy Iteration)과 동일하다.
-
GPI 에서는 근사 정책과 근사 가치함수를 모두 유지한다.
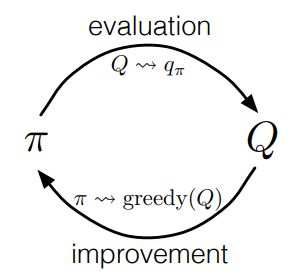
- 가치함수는 현재 정책의 가치함수에 더 근접하도록 반복적으로 변경되며, 정책은 현재 가치함수에 대해 반복적으로 개선됨.
- 이 두 종류의 변화는 각각 서로에게 움직이는 목표를 생성하기 때문에, 어느 정도 서로에게 불리하게 작용하지만, 정책과 가치함수 모두 최적에 접근하게 됨.
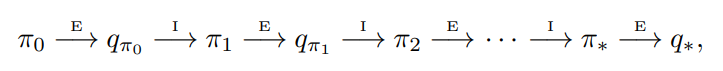
- 우선, 고전적인 정책 반복의 몬테카를로 버전을 살펴보면 임의의 정책 $\pi_0$ 에서 시작하여 최적 정책 및 최적 행동가치함수로 끝나는 정책 평가 및 정책 개선의 전체 단계를 번갈아 가며 수행한다.
- 여기서 $\overset{E}{\rightarrow}$ 는 완전한 정책 평가를 나타내며, $\overset{I}{\rightarrow}$ 는 완전한 정책 개선을 나타낸다.
- 정책 평가는 이전 섹션에서 설명한 대로 수행된다.
- 실제 행동가치함수에 점근적으로 접근하기 위해, 많은 에피소드를 경험하게 된다.
- 우리는 탐색 시작(exploring starts) 으로 생성되는 무한한 수의 에피소드를 관찰한다고 가정한다.
- 이러한 가정 하에 몬테카를로 방식은 임의의 $\pi_k$ 에 대해 $q_{\pi_k}$ 를 정확하게 계산한다.
- 정책 개선은 현재 가치함수 기반으로 정책을 탐욕화 하여 이루어짐
- 이 경우 우리는 행동가치함수를 가지고 있으므로, 탐욕 정책을 만드는데 환경 모델은 불필요하다.
- 어떠한 행동가치함수 $q$ 에서도, 상응하는 탐욕 정책은 하나이다. (모든 $s \in S$ 에 대해 결정론적으로 최대값을 가지는 행동을 선택할 경우)

- 정책 개선은 $q_{\pi_k}$ 에 대한 탐욕 정책 $\pi_{k+1}$ 을 설계함으로서 이루어진다.
- 이 경우 policy improvement theorem 이 적용된다.
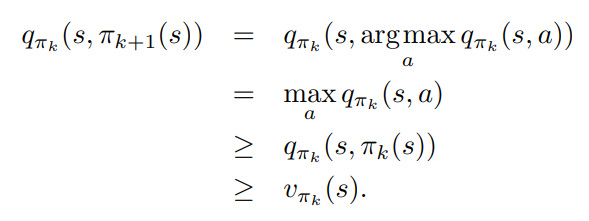
- 앞 장에서 이야기했던 것처럼 위 정리는 $\pi_{k+1}$ 이 $\pi_k$ 보다 균일하게 낫거나, 같음 (최적 정책일 경우) 을 보장한다.
- 위의 내용을 기반으로 전체 프로세스가 최적 정책과 최적 가치함수로 수렴을 진행한다는 것을 확신할 수 있음.
- 이러한 방식으로 몬테카를로 방식을 사용하여 환경 역학 지식 없이 샘플 에피소드만으로 최적의 정책을 찾을 수 있음.
- 몬테카를로 방식을 사용하기 위한 가정과 실제 해결책
- 몬테카를로 수렴 보장을 위한 현실적이지 않은 가정
- 에피소드가 탐색 시작 (exploring starts) 을 한다는 점
- 무한히 많은 에피소드로 정책 평가를 할 수 있다는 점
- 실용적인 알고리즘을 얻으려면 위 두 가지 가정을 모두 제거해야 함.
- 이 장의 뒷부분 까지 우리는 첫 번째 가정에 대한 고려를 연기한다.
- 지금은 정책 평가가 무한한 수의 에피소드에서 작동한다는 가정에 초점을 맞춘다.
- 무한한 수의 에피소드 진행을 피하는 방법
- 사실 반복 정책 평가 (iterative policy evaluation) 와 같은 고전적인 DP 방법에서도 동일한 문제가 발생함. (이 역시 참 가치 함수에 점근적으로만 수렴한다.)
- DP 와 몬테카를로 모두, 문제를 해결하는 두 가지 방법이 있다.
- 각 정책 평가에서 $q_{\pi_k}$ 를 근사화한다는 아이디어를 확고히 유지하고, 측정과 가정을 통해 추정치의 오차 크기와 확률에 대한 한계를 얻고, 그런 다음 각 정책 평가 중에 충분한 단계를 취하여 이러한 한계가 충분히 작음을 보장함.
- 어느 정도의 근사 수준까지 올바른 수렴을 보장
- 그러나 가장 작은 문제들을 제외한 모든 실 문제에 유용하려면 너무 많은 에피소드가 필요할 수도 있음.
- 정책 개선으로 돌아가기 전에 정책 평가를 완료하려는 시도를 포기함.
- 각 평가 단계에서 가치함수를 $q_{\pi_k}$ 쪽으로 이동시키지만, 많은 단계를 거쳐야만 가까워짐.
- GPI 개념과 동일한 방식의 아이디어를 사용함.
- 예를들어 value iteration 과 같이 정책 개선 사이에 정책 평가를 한 번만 수행. (in-place 버전의 경우 몇몇의 상태만 정책평가를 한 후 정책 개선을 진행)
- 몬테카를로 수렴 보장을 위한 현실적이지 않은 가정
- 몬테카를로 ES (Monte Carlo with Exploring Starts)
- 몬테카를로 정책 반복의 경우 에피소드 별로 평가와 개선을 번갈아 가며 수행하는 것이 자연스러움.
- 각 에피소드 후에 관찰된 리턴값은 정책 평가에 사용되며 에피소드에서 방문한 모든 상태에서 정책이 개선됨.
- 몬테카를로 ES (Monte Carlo with Exploring Starts) 라고 부르는 간단한 알고리즘은 아래의 psuedo-code 와 같은 형태이다.

- 몬테카를로 ES 에서 각 상태-행동 쌍에 대한 모든 리턴값은 관찰 당시 시행중인 정책에 관계 없이 누적 되고 평균화됨.
- 즉 몬테카를로 ES 는 차선 정책으로 수렴할 수 없음.
- 만약 그럴 경우 가치함수가 차선 정책으로 수렴하면서 정책이 변경됨.
- 안정성은 정책과 가치함수 모두 최적일 때만 달성됨.
- 행동가치함수의 변화가 시간이 지남에 따라 감소하면서, 최적의 고정점으로의 수렴은 불가피해 보이지만 아직 공식적으로 증명되지 않았음.
- 이것은 강화 학습에서 가장 기본적인 미해결 이론적 질문 중 하나임.
- 행동가치함수의 변화가 시간이 지남에 따라 감소하면서, 최적의 고정점으로의 수렴은 불가피해 보이지만 아직 공식적으로 증명되지 않았음.
- Example 5.3 : Solving Blackjack
- 몬테카를로 ES 를 블랙잭에 적용하는 것은 간단함.
- 에피소드는 모두 시뮬레이션 게임이기 때문에 모든 가능성을 포함하는 탐색 시작의 준비가 쉬움.
- 이 경우 딜러의 카드, 플레이어의 합계, 플레이어가 사용 가능한 에이스를 가지고 있는지 여부를 모두 동일 확률로 무작위 선택함.
- 초기 정책으로 이전 블랙잭의 예시에서 평가된 정책을 사용하며, 20 또는 21에만 적용됨.
- 초기 행동가치함수는 모든 상태-행동 쌍에 대해 0 로 설정.
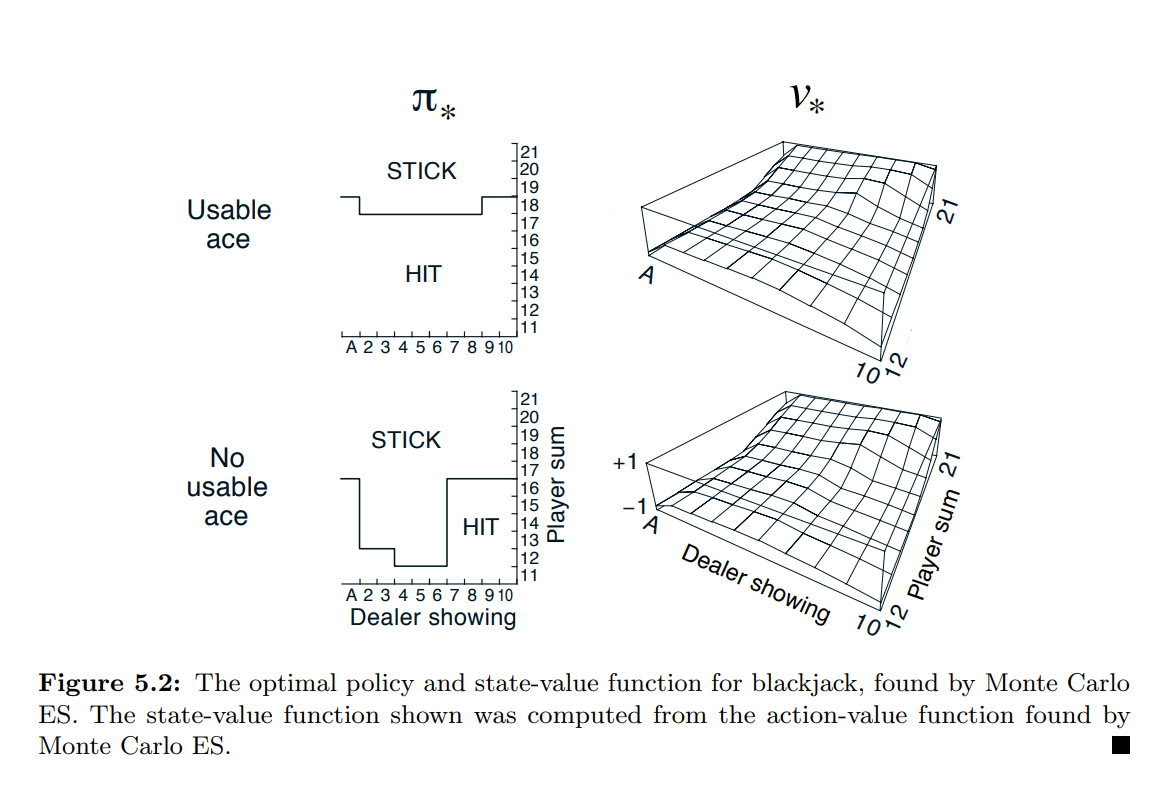
- Figure 5.2 는 몬테카를로 ES 가 찾아낸 최적의 정책을 보여줌.
- 이 정책은 사용 가능한 에이스에 대한 정책에서 가장 왼쪽 노치를 제외하고 Thorp(1966)의 “기본” 전략과 동일함.
- 이러한 불일치의 이유는 확실하지 않지만, 여기에 표기된 것이 실제로 우리가 설명한 블랙잭 버전의 최적 정책이라고 확신할 수 있다.
- 몬테카를로 제어(Control) 와 GPI (Generalized Policy Iteration)
- Monte Carlo Control without Exploring Starts
- On-policy 방식과 Off-policy 방식
- 탐색 시작 (Exploring starts) 이라는 희박한 가정을 피하기 위해, 모든 행동이 무한정으로 자주 선택되도록 에이전트가 해당 행동을 계속 선택하는 방식이 있다.
- 이를 보장하는 두 가지 접근 방식이 있으며, 이를 On-policy 방식과 Off-policy 방식이라고 부른다.
- On-policy 방식 : 학습 정책과 탐색 정책이 동일한 경우를 가리킴 (탐색 정책을 사용하여 데이터를 수집하고 학습(정책개선)을 진행)
- Off-policy 방식 : 학습 정책과 탐색 정책이 다른 경우 (학습 정책은 실제로 개선하고자 하는 정책, 탐색 정책은 환경 탐색, 경험을 얻기 위한 정책)
- 위의 몬테카를로 ES 방식은 On-policy 방식의 한 예이다.
- 이 섹션에서는 On-policy 몬테카를로 제어 방법의 설계에 대해 다루며, Off-policy 정책은 다음 섹션에서 고려한다.
- On-policy 제어 방식
- 일반적으로 on-policy 제어 방식은 soft 하다.
- 즉, $\pi (a | s) > 0$ for all $s \in S$ and all $a \in A(s)$
- 점차적으로 결정론적 최적 정책에 가까워진다.
- 이 장에서의 on-policy 방식은 $\varepsilon -greedy$ 정책을 사용한다.
- 대부분은 행동가치 추정값이 최대인 행동을 선택하나, $\varepsilon$ 의 확률로 임의의 행동을 선택한다.
- 모든 탐욕적이지 않은 행동은 최소의 선택 확률 $\frac{\varepsilon}{| A(s) |}$ 을 가지며, 탐욕 행동은 $1-\varepsilon + \frac{\varepsilon}{| A(s) |}$ 의 확률을 가진다.
- (집합을 절대값 기호로 묶은 표기는 해당 집합의 원소 수를 나타낸다.)
- $\varepsilon - greedy$ 정책은 $\varepsilon - soft$ 정책의 한 예이다.
- 모든 상태와 행동에 대해, $\pi (a | s) \ge \frac{\varepsilon}{ | A(s) |}$ 이며, $\varepsilon > 0$
- $\varepsilon - greedy$ 정책은 $\varepsilon - soft$ 정책 중에서도 탐욕 정책에 가장 가까운 정책이다.
- On-policy 몬테카를로 제어의 전반적인 아이디어는 여전히 GPI 의 아이디어이다.
- 몬테카를로 ES 와 마찬가지로 이번에도 first-visit MC 방식 으로 현 정책의 행동가치함수를 추정한다.
- 그러나 탐색 시작의 가정 없이 현재 가치함수를 탐욕정책으로 개선할 수 없다. (탐욕스럽지 않은 행동의 추가 탐색을 방지할 수 있음.)
- GPI 는 정책이 탐욕정책으로 완전히 전환되는 것을 요구하지 않고, 탐욕정책의 바향으로 이동하기만 하면 됨.
- On-policy 방식에서는 $\varepsilon - greedy$ 정책으로 이동할 것임.
- $q_\pi$ 에 대한 $\varepsilon - soft$ 정책, $\varepsilon - greedy$ 정책 은 $\pi$ 와 같거나 더 나음을 보장한다.
- 아래는 전체 알고리즘에 대한 내용이다.

- $q_\pi$ 에 기반한 어떠한 $\varepsilon - greedy$ 정책도 $\varepsilon - soft$ 정책보다 개선된다는 점은 policy improvement theorem 에 의해 보장된다.
- $\pi’$ 를 $\varepsilon - greedy$ 정책이라 가정하면 아래의 수식이 성립된다.
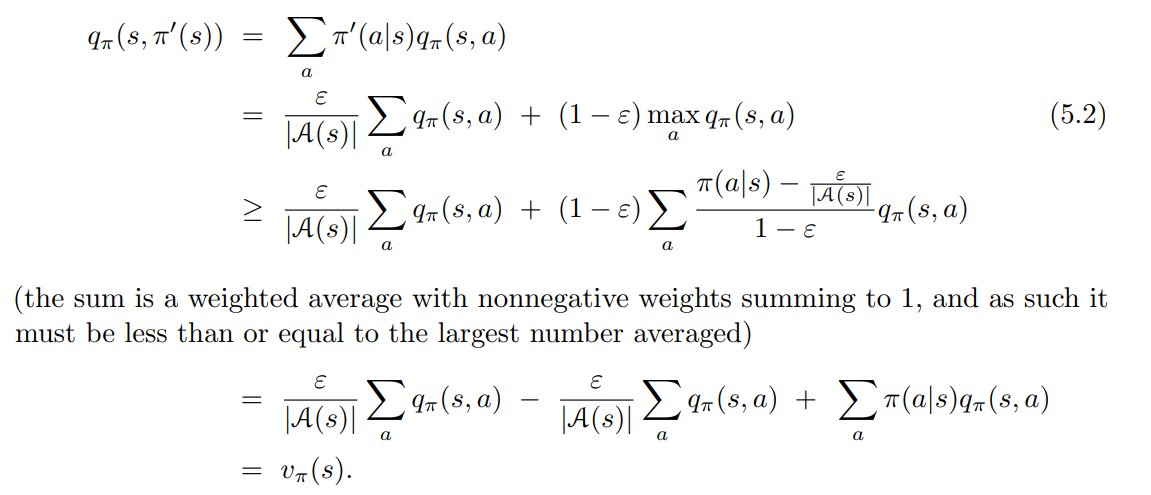
- policy improvement theorem 에 따라, $\pi’ \geq \pi$ (i.e., $v_{\pi’} (s) \geq v_\pi (s)$, for all $s \in S$).
- 이때 등식은 $\pi’$ 와 $\pi$ 모두 $\varepsilon - soft$ 정책 내에서 최적이며, 동시에 모든 타 $\varepsilon - soft$ 정책보다 좋거나 같을 때 성립한다.
- $\varepsilon - soft$ 정책이 환경 내부로 이동한, 원래 환경과 동일한 새 환경을 고려한다.
- 새 환경은 원 환경과 동일한 행동, 동일한 상태 설정을 가진다.
- 만약 상태 s 에서 행동 a 를 취하는 경우, 확률 $1 - \varepsilon$ 으로 새 환경은 이전 환경과 동일하게 작동한다.
- $\varepsilon$ 의 확률로, 같은 확률분포로 임의의 행동을 재선택하면, 새로운 행동을 선택한 이전의 환경처럼 동작한다.
- 보통의 정책으로 이 새로운 환경에서 할 수 있는 최선은, $\varepsilon - soft$ 정책으로 원래 환경에서 할 수 있는 최선과 동일함.
- $\tilde{v_*}$ 는 새로운 환경에 대한 최적 가치함수를 나타냄.
- $v_\pi = \tilde{v_*}$ 인 경우에만 정책 $\pi$ 가 $\varepsilon - soft$ 정책 중에서 최적임.

- 이 방정식은 $\tilde{v_*}$ 를 $v_\pi$ 로 치환한 것을 제외하고 이전 것과 동일하다.
- $\tilde{v_*}$ 는 고유 솔루션이다.
- 따라서 $v_\pi = \tilde{v_*}$ 여야만 한다.
- 지금까지 $\varepsilon - soft$ 정책에도 정책 반복이 작동한 다는 것을 살펴봄.
- 탐욕 정책의 자연스러운 개념을 사용하면, $\varepsilon - soft$ 정책 중에서 최상의 정책이 발견된 경우를 제외하고 모든 단계에서 개선이 보장됨.
- 이 분석은 각 단게에서 행동가치함수가 결정되는 방식과 별개이나, 정확하게 계산된다고 가정하였다.
- 한편으로 이는 탐색 시작이라는 가정을 없앤 것임.
- 일반적으로 on-policy 제어 방식은 soft 하다.
- On-policy 방식과 Off-policy 방식
-
Off-policy Prediction via Importance Sampling
- Off-policy learning 의 정의
- 모든 제어(Control) 에 대한 학습방법은 딜레마에 직면함.
- 그들은 후속 최적 행동에 대해 조건부로 행동값을 학습하려고 함.
- 모든 행동을 탐색하기 위해 최적이 아닌 행동을 해야 함.
- 탐색적 정책에 따라 행동하는데 최적의 정책에 알수 있는 방법
- On-policy 방식 : 절충안
- 최적의 정책이 아니라 여전히 탐색하는 최적에 가까운 정책에 대한 작업 값을 학습함.
- Off-policy 방식 : 보다 직접적인 접근방식
- 학습되어 최적의 정책이 되는 정책 (대상정책 : target policy) 과 탐험을 하며 행동을 생성하는 정책 (행동정책 : behavior policy)
- 학습이 대상 정책에서 떨어진 (off) 데이터에서 발생한다 : Off-policy learning
- On-policy 방식 : 절충안
- 모든 제어(Control) 에 대한 학습방법은 딜레마에 직면함.
- On-policy 와 Off-policy
- 이 책의 나머지 부분에서는 On-policy 방식과 Off-policy 방식 모두를 고려함.
- On-policy 방식
- 일반적으로 더 간단
- 먼저 고려되는 방식
- Off-policy 방식
- 추가 개념과 표기법이 필요하며, 데이터가 다른 정책의 것이기 때문에 분산이 더 크고, 수렴 속도가 느림.
- 더 강력하고 일반적임.
- 특이 케이스로 대상 정책 (target policy) 과 행동 정책 (behavior policy) 이 같으면 On-policy 방식이 된다. (포함)
- 응용 프로그램에서 더 많은 쓰임새가 있음.
- 기존의 비학습 컨트롤러 또는 인간 전문가가 생성한 데이터를 학습할 수도 있음.
- 일부 사람들에게는 세상의 동적 모델을 학습하는 다단계 예측 모델을 배우는 데 중요한 역할을 하는 것으로 간주됨.
- Off-policy 방식
- 대상정책 (target policy) 과 행동정책 (behavior policy) 이 모두 고정된 예측 문제를 가정
- 즉, $v_\pi$ 또는 $q_\pi$ 를 추정하려 하나, 우리가 가진 데이터는 정책 $b$ 를 따르는 에피소드 뿐이라고 가정. ($b \ne \pi$)
- 이 경우, $\pi$ 는 대상정책, $b$ 는 행동정책이며, 두 정책 모두 고정 및 주어진 것으로 간주한다.
- 커버리지 가정 (assumption of coverage)
- $b$ 의 에피소드를 사용하여 $\pi$ 의 값을 추정하려면, $\pi$ 에서 취한 모든 작업이 $b$ 에서도 적어도 가끔씩 수행되어야 함.
- 즉, $\pi (a | s) > 0$ 이면 $b (a | s)$ 를 요구한다.
- 커버리지 가정의 적용 범위 내에서 $b$ 는 $\pi$ 와 동일하지 않은 상태에서 확률론적이어야 함.
- 반면 목표정책 $\pi$ 는 결정론적일 수 있으며, 제어 응용프로그램에서 특히 중요한 사항임.
- 제어 측면에서, 대상정책은 일반적으로 행동가치함수의 현재 추정치의 결정론적 탐욕 정책임.
- 대상정책이 결정론적 최적 정책이 되는 반면, 행동정책은 확률론적이고 탐색적임. (예 : $\varepsilon - greedy$ 정책)
- 이 섹션에서는, $\pi$ 가 변하지 않고, 주어진 예측 문제를 고려함.
- 대상정책 (target policy) 과 행동정책 (behavior policy) 이 모두 고정된 예측 문제를 가정
- 중요도 샘플링 (importance sampling)
- 거의 모든 Off-policy 방식은 중요도 샘플링 (importance sampling) 을 활용함.
- 중요도 샘플링은 다른 분포에서의 샘플을 통해 하나의 분포에서의 기댓값을 추정하는 일반적인 기법임.
- 중요도 샘플링 비율 (imporatnce-sampling ratio)
- 대상정책 (target policy) 과 행동정책 (behavior policy) 에 따른 경로 발생의 상대적 확률에 따라 리턴 값에 부여하는 가중치
- $S_t$ 에서 시작하여, 정책 $\pi$ 하에 후속 상태-행동 궤적 ($A_t, S_{t+1}, A_{t+1}, \cdots , S_T$) 의 확률은 아래와 같다.
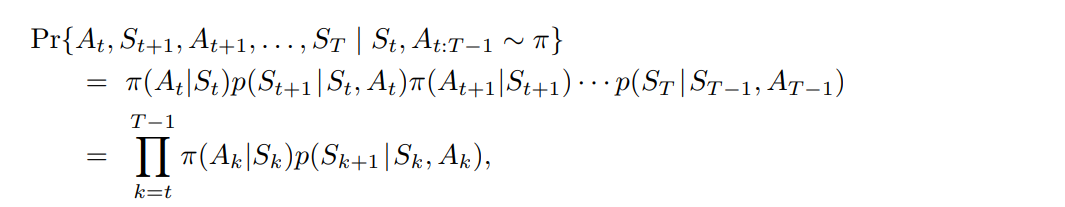
- 여기에서 $p$ 는 상태전이확률 함수이다.
- 따라서, 대상정책과 행동정책 간 궤적의 상대적 확률 (importance-sampling ratio) 은 아래와 같다.
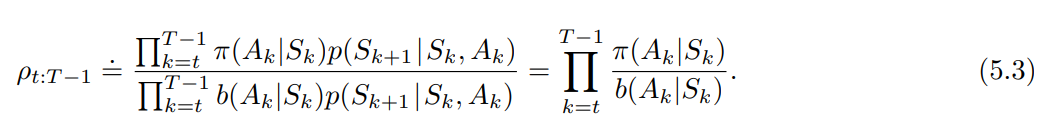
- 궤적 확률은 일반적으로 알려지지 않은 MDP의 전이확률에 의존하지만, 분자와 분모 모두에 동일하게 나타나 상쇄된다.
- 중요도 샘플링 비율은 MDP 가 아닌, 두 정책과 시퀀스에만 의존하게 된다.
- 우리가 원하는 추정값은 대상정책(traget policy) 의 기대되는 리턴값이다.
- 실제로 가진 값은 행동정책(behavior policy) 의 리턴값 $G_t$ 이다.
- 즉, $\mathbb{E}[G_t | S_t = s] = v_b(s)$ 이며, 이를 이용해 평균값을 구하여 $v_\pi$ 를 얻는 것은 불가능하다.
- 이 부분에서 중요도 샘플링 (importance sampling) 개념이 필요하다.
- 즉, ratio $p_{t:T-1}$ 값이 리턴값을 변환시켜, 올바른 예측값을 구하게 된다.
- $\mathbb{E}[p_{t:T-1}G_t | S_t = s] = v_\pi (s)$
- 중요도 샘플링 (importance sampling) 을 활용한 가치함수추정
- 이제 우리는 $v_\pi(s)$ 를 추정하기 위해 정책 $b$ 의 관찰된 에피소드 배치의 평균 리턴값을 계산하는 몬테카를로 알고리즘이 준비되었다.
- 여기에서 에피소드의 경계를 넘어 증가하는 방식으로 타임스텝 (time step) 번호를 지정하는 것이 편리하다.
- 즉, 배치의 첫 에피소드가 time step = 100 에서 종료했다면, 다음 에피소드는 t = 101 에서 시작됨.
- 이를 통해 특정 에피소드의 특정 타입스텝을 참조하기 위해 time-step number 를 사용할 수 있다.
- 수식 내 문자의 의미
- $\mathcal{T} (s)$ : 상태 s 를 방문하는 모든 time-step number 집합
- 이것은 every-visit 방식에 해당하는 의미이며, first-visit 방식의 경우 $\mathcal{T} (s)$ 는 에피소드 내 s를 처음 방문한 time-step number 만 포함한다.
- $T(t)$ : 시간 t 이후 첫 번째 종료를 의미
- $G_t$ : t 이후 $T(t)$ 까지의 리턴값
- ${G_t}_{t \in \mathcal{T}(s)}$ : 상태 s 에 속하는 리턴값
- ${p_{t:T(t)-1}}_{t \in \mathcal{T}(s)}$ : 위에 상응하는 중요도 샘플링 비율
- $\mathcal{T} (s)$ : 상태 s 를 방문하는 모든 time-step number 집합
- Ordinary Importance Sampling : $v_\pi (s)$ 를 추정하기 위해, 간단히 리턴 값을 비율로 조정하고 평균값을 구하는 수식은 아래와 같다.

- Weighted Importance Sampling : 0이 아닌 평균의 가중치 (weighted average) 를 사용한다.

- Ordinary Importance Sampling 과 Weighted Importance Sampling
- 두 가지 종류의 중요도 샘플링을 이해하기 위해, 한 번의 리턴을 관찰한 후 first visit 방법 의 추정치를 고려해보자.
- 평균의 가중치 추정 (weighted-average estimate) (Weighted Importance Sampling의 경우) 에서는 단일 리턴에 대한 비율 $p_{t:T(t)-1}$ 이 분자와 분모에서 상쇄되어, 비율과 관계없이 추정치는 관찰된 리턴과 동일하게 됨. (비율이 0이 아닌 경우를 가정)
- 이 관찰된 리턴이 유일하게 관찰된 경우에는 합리적인 추정치이지만, 기대값은 $v_b(s)$ 가 아닌 $v_\pi (s)$ 이며, 이 통계적 의미에서 편향된 추정치이다.
- 반면 일반 중요도 샘플링 (Ordinary Importance Sampling) 추정의 first visit 버전은 항상 기대값이 $v_\pi (s)$ 이다. (편향이 없는 추정치)
- 하지만 이는 극단적일 수 있음.
- 예를 들어 가중치 비율이 10이라고 가정해보면, 이는 관측된 경로가 행동정책에 비해 대상정책에서 10배 더 가능성이 높다는 의미이다.
- 이 경우 일반 중요도 샘플링 (Ordinary Importance Sampling) 의 추정치는 관측된 리턴의 10배가 된다.
- 즉, 관측된 보상과는 상당히 멀어질 것이며, 이는 해당 에피소드의 경로가 대상정책을 매우 잘 대표한다고 생각되더라도 그렇다.
- 형식적으로, 두 종류의 중요도 샘플링의 첫 방문 방법의 차이는 편향과 분산으로 표현된다.
- 일반 중요도 샘플링은 편향이 없지만, 가중 중요도 샘플링은 편향이 존재한다. (편향은 점진적으로 0으로 수렴함.)
- 일반 중요도 샘플링의 분산은 일반적으로 무한대일 수 있다.
- 비율의 분산이 무한대일 수 있기 때문
- 반면 가중 샘플링 방식의 추정치에서는 단일 리턴값의 가장 큰 가중치는 1이다.
- 실제로 유한한 리턴값을 가정하면, 가중 중요도 샘플링 추정치의 분산은 비율의 분산 자체가 무한대일지라도 0으로 수렴함 (Precup, Sutton, and Dasgupta 2001)
- 가중 추정치의 분산은 일반적으로 매우 낮고 강력하게 선호된다.
- 함수 근사를 사용한 근사 방법을 더 쉽게 확장할 수 있기 때문에, 일반 중요도 샘플링 또한 학습할 것이다.
- 일반 중요도 샘플링과 가중 중요도 샘플링의 every visit 방식은 모두 편향이 있으며, 샘플의 수가 증가함에 따라 편향은 0으로 수렴한다.
- every visit 방식은 방문한 상태를 추적할 필요가 없으며, 근사화에 쉽게 확장할 수 있기 때문에 선호되는 편이다.
- 부연설명 (가치함수 V(s)를 구하는 Ordinary Importance Sampling과 Weighted Importance Sampling의 수식)
- Ordinary Importance Sampling
- $V(s) = \frac{1}{N} * \sum [ W(i) * R(i) ]$
- N : 수집된 샘플의 개수
- $W(i)$ : i 번째 샘플의 가중치
- $R(i)$ : i 번째 샘플의 보상
- $V(s) = \frac{1}{N} * \sum [ W(i) * R(i) ]$
- Weighted Importance Sampling
- $V(s) = \sum [ \frac{(W(i) * R(i))}{\sum W(i)} ]$
- $W(i)$ : i 번째 샘플의 가중치
- $R(i)$ : i 번째 샘플의 보상
- $\sum W(i)$ : 가중치의 합
- Ordinary Importance Sampling 은 모든 샘플이 동일한 중요도 ($\frac{1}{N}$) 를 가짐 (평균을 구함)
- Weighted Importance Sampling 은 각 샘플마다 개별적인 중요도를 가짐. ($\frac{W(i)}{\sum W(i)}$)
- $V(s) = \sum [ \frac{(W(i) * R(i))}{\sum W(i)} ]$
- Ordinary Importance Sampling
- Off-policy learning 의 정의
Introduction to Monte Carlo Methods
- What is Monte Carlo?
- 소개
- 몬테카를로 라는 용어는 반복적으로 무작위 샘플링에 의지하는 추측방식을 광범위하게 일컷는 용어로 많이 쓰임.
- 강화학습에서는 상태의 시퀀스, 행동, 보상등의 경험으로부터 직접적으로 추정값에 접근하는 방식임.
- 경험으로부터 직접 학습한다는 것은 강력한 이점인데, 환경역학에 대한 사전지식 없이 정확한 가치함수를 추정할 수 있기 때문
- 학습 목표
- 몬테카를로 방식이 샘플링된 상호작용을 통한 가치함수 예측에 어떻게 쓰이는지 이해하기
- 몬테카를로 방식을 통해 풀 수 있는 문제 식별하기
- 강화학습에서 DP 학습의 한계점
- 에이전트는 환경의 상태변이확률을 알고 있어야 함.
- 예를 들어, 기상학자가 미래의 기상 예측을 할 때, 환경의 상태변이확률을 알 수가 없음.
- 상태변이확률을 계산하는 것도 어렵고 에러 발생이 큰 지루한 작업임.
- 12개의 주사위를 던지는 문제일 때, DP의 계산은 코딩 혹은 계산 정확성에서 지루하고 오류가 발생하기 쉬운 작업임.
- 합계 12가 나올 확률, … , 합계 72가 나올 확률을 계산하는 것
- 몬테카를로 방식에서는 많은 무작위 샘플을 이용해 평균을 구하고, 값을 추정함.

- 12개의 주사위의 기대 합 42와 근접한 수치의 추측
- 12개의 주사위를 던지는 문제일 때, DP의 계산은 코딩 혹은 계산 정확성에서 지루하고 오류가 발생하기 쉬운 작업임.
- 에이전트는 환경의 상태변이확률을 알고 있어야 함.
-
몬테카를로 방식
- 몬테카를로 방식을 이용한 가치함수 추정
- 동일한 상태에서 여러 리턴값을 관찰
- 이 다수의 리턴값의 평균을 구해 해당 상태의 추정 리턴값을 구함.
- 샘플의 수가 많아질수록, 실제 값에 가까워짐.
-
이러한 리턴 값은 에피소드가 끝나야 알 수 있음. (Episodic Tasks 라 가정)
- 몬테카를로 방식과 bandit 방식
- 몬테카를로와 bandit 방식은 유사한데, badnit 에서도 arm 을 여러번 당겨 평균값을 구해 추정값을 구했었음.
-
몬테카를로의 차이점은 arm 이 아닌 정책을 고려한다는 점이다.
- 몬테카를로 방식의 리턴 값 계산

- 효율적인 계산을 위해 에피소드 종료시점 부터 거꾸로 계산해야 함.

- 평균을 구할 때, 이전의 값들을 모두 저장하는 것이 아닌 증분 업데이트의 사용이 가능하다.
- $NewEstimate \gets OldEstimate + StepSize [Target - OldEstimate]$
- 소개
- Using Monte Carlo for Prediction
- 학습 목표
- 몬테카를로 예측을 통해 주어진 정책의 가치 함수를 예측하기
- 학습 목표
Monte Carlo for Control
-
Using Monte Carlo for Action Values
- 학습 목표
- 몬테카를로 방식을 통해 행동 가치함수 (action value function) 추정하기
- 몬테카를로 알고리즘에서 탐색의 유지의 중요성을 이해하기
- Learning Action Values
- 상태의 값을 추정하는 방식과 동일 (특정 상태에서 행동을 선택했을 때의 리턴값의 평균을 구함)\
- 행동 가치를 학습하는 이유
- 하나의 상태에서 각 행동이 가지는 가치비교를 할 수 있음.
- 더 나은 행동으로의 정책 변경이 가능
- 이는 다른 행동을 하여 가치를 추정했을 때 가능함.
- 이 부분이 어려운 부분인데, 결정론적인 정책을 따를 경우 다른 행동을 탐색하지 않는다. (정책을 따름)
- 탐색의 유지 문제
- 에이전트는 값들을 학습을 위해 각 상태의 모든 행동을 시도해봐야 한다.
- exploring starts (탐색 시작)
- 모든 상태-행동 쌍에서 첫 시작을 해보는 것을 보증해야한다.
- 그 뒤로 에이전트는 정책을 따라 움직인다.
-
Using Monte Carlo methods for generalized policy iteration
- 학습 목표
- 몬테카를로 방식을 사용하여 GPI (Generalized Policy Iteration) 알고리즘 구현하는 방법 이해하기
-
Monte Carlo Generalized Policy Iteration
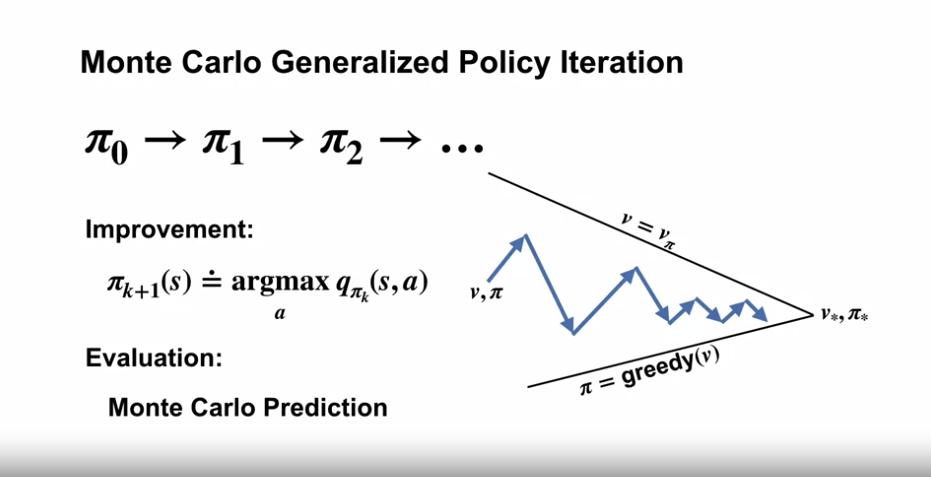
- 정책 평가를 Monte Carlo Prediction 으로 진행 (샘플링된 에피소드의 평균을 통한 행동가치함수의 추정)
- 탐색 유지를 위한 여러 방법 중 하나를 사용 (여기에서는 탐색시작 방법을 사용한다.)
- 정책 개선을 $q_{\pi_k}$ 의 $\arg\max$ 함수를 이용해 탐욕적으로 개선

- 정책 평가를 Monte Carlo Prediction 으로 진행 (샘플링된 에피소드의 평균을 통한 행동가치함수의 추정)
- 학습 목표
-
Solving the Blackjack Example
- 학습 목표
- MDP 해결을 위한 탐색 시작과 함께 몬테 카를로의 적용
- 몬테카를로 방식의 블랙잭 적용 예시
- 문제의 정의
- 각 블랙잭 게임을 하나의 에피소드로 보고, 할인되지않은 MDP 를 적용한다.
- 보상 : 패배시 -1, 비길 시 0, 이길 시 1
- 행동 : 힛, 스틱
- 상태 : 에이스가 있는지 여부, 플레이어 카드의 총합, 딜러의 카드 1장
- 위의 경우 총 200개의 상태가 존재한다.
- 덱의 모든 카드를 교체나 버리는 것 없이 사용한다고 가정한다. (카드카운팅 불가 : 현 상태로 마르코브 속성을 가짐.)
- 몬테카를로 적용
- 에이전트는 하나의 에피소드가 끝나고 학습이 가능
- Discount factor 가 1이기 때문에, 승리했을 경우 해당 에피소드의 각 상태에서의 보상값은 1이다.
- 몬테카를로의 장점
- 환경의 거대한 모델을 저장할 필요가 없음
- 특정 상태에 대한 값을 개별적으로 측정할 수 있다. (타 상태의 값과 관계없이)
- 값의 업데이트 계산에 MDP의 상태집합의 크기가 영향을 주지 않는다. (에파소드의 길이에 영향을 받음)
- 문제의 정의
- 블랙잭의 조건
- Exploring Starts 를 사용하기 좋은 조건 (에피소드 시작을 무작위 상태에서 무작위 행동을 하는 것으로 시작한다.)
- 현재의 블랙잭 게임 조건은 자연스럽게 랜덤한 상태에서 시작하게 된다. (플레이어 손패 카드 2장 (에이스 유무와 합계), 딜러 패 2장중 1장 오픈)
- 즉, 첫 행동을 무작위로 선택하면 되는데, 정책을 따르는 것은 그 이후에 하게 됨. (합이 20이 넘으면 스틱)
- Exploring Starts 를 사용하기 좋은 조건 (에피소드 시작을 무작위 상태에서 무작위 행동을 하는 것으로 시작한다.)
- 학습 목표
Exploration Methods for Monte Carlo
-
Epsilon-soft Policy
- 학습 목표
- 왜 탐색 시작이 실 문제에서 적용이 어려운지 이해하기
- 몬테카를로 제어를 위한 대안적 탐색유지 방법의 설명
- 탐색 시작을 사용할 수 없는 경우
- 탐색 시작 알고리즘은 모든 가능한 상태와 행동 쌍에서 시작할 수 있어야 한다.
- 그렇지 않은 경우 충분한 탐색을 하지 못하므로, 최적 정책이 아닌 차선의 다른 정책에 수렴하게 될 수 있다.
- 대부분의 문제는 시작 상태-행동 쌍으로 무작위 샘플을 구할 수 없다.
- 예를 들어 자율주행 문제의 경우 초기 상태-행동 쌍을 무작위 샘플링할 수 없다. (닥칠 수 있는 모든 상황-행동으로 초기화 시작)
- 탐색 시작 알고리즘은 모든 가능한 상태와 행동 쌍에서 시작할 수 있어야 한다.
-
e-Greedy 탐색

- $\varepsilon-Greedy$ 정책
- Bandits 에서 사용했던 $\varepsilon-Greedy$ 을 몬테카를로에 적용
- $\varepsilon-Greedy$ 정책은 확률론적인 정책임
- 보통 탐욕적인 행동을 취하나 때로는 무작위 행동을 선택함.
- $\varepsilon-Soft$ 정책
- $\varepsilon-Greedy$ 정책 을 포괄하는 정책
- 각 행동에 $\frac{\epsilon}{ | \mathcal{A} |}$ (nonzero) 이상의 확률을 부여
- 필연적으로 모든 행동을 시도하게
- $\varepsilon-Soft$ 정책은 에이전트로 하여금 계속 탐색하도록 강제한다.
- 즉, 탐색 시작의 요구사항을 제거 (탐색 시작을 대체) 할 수 있음.
- $\varepsilon-Greedy$ 정책
-
$\varepsilon-Soft$ 정책의 한계
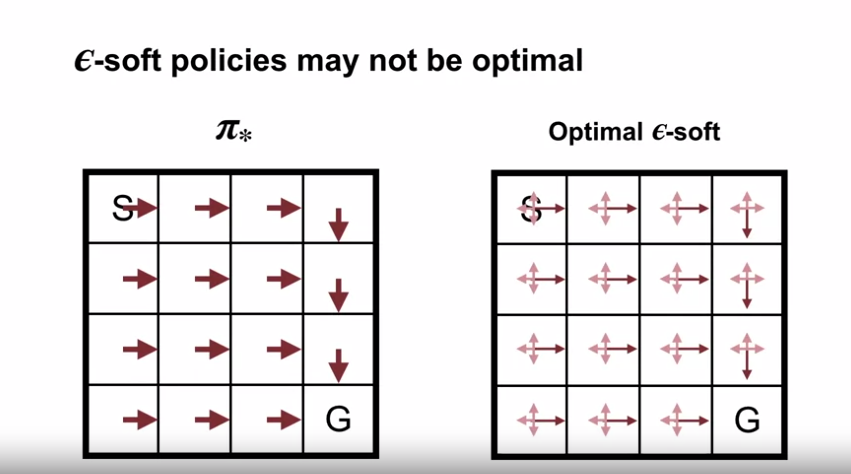
- 결정론적 최적 정책에 수렴할 수 없다.
- 탐색 시작의 방식은 최적 정책에 도달함과 다르게, 최적 $\varepsilon-Soft$ 정책 에만 도달할 수 있음.

- 위 코드는 몬테카를로 $\varepsilon-Soft$ 정책에 대한 내용으로, 탐색시작과 차이가 생기는 부분을 표시한 것이다.
- 결정론적 최적 정책에 수렴할 수 없다.
- 학습 목표
Off-policy Learning for Prediction
-
Why does off-policy learning matter?
- 학습 목표
- off-policy learning 이 탐색 문제를 해결하는 데 어떻게 도움이 되는지 이해하기
- 목표 정책의 예시 및 행동 정책의 예시를 생성
-
$\varepsilon - soft$ 정책의 한계점
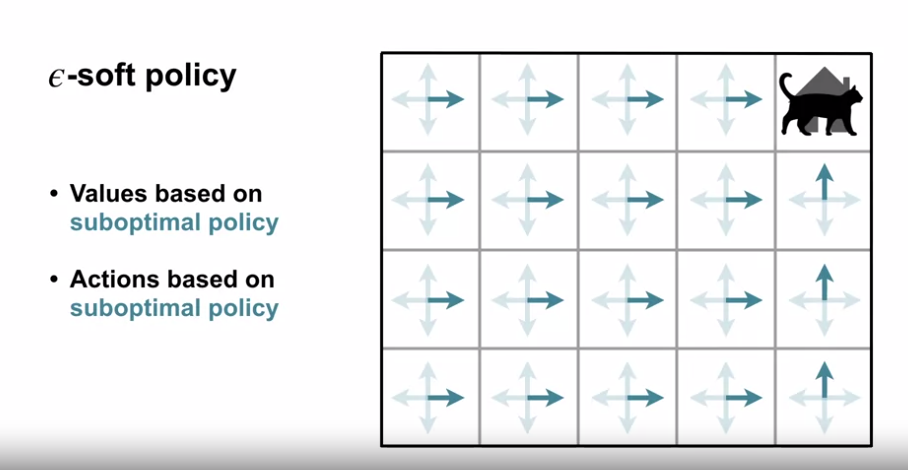
- 탐색에도, 행동에도 최적 정책이 아니다.
- 학습을 통해 차선의 최적 정책으로 수렴함.
- On-Policy 와 Off-Policy
- On-Policy Learning: 에이전트가 학습할 데이터의 생성에 기여한 정책을 발전시킴.
- Off-Policy Learning: 에이전트가 다른 정책으로부터 학습할 데이터를 생성하여 이와 별개의 정책을 학습
- 예를들어 uniform random 정책으로 생성한 데이터로 최적 정책을 학습함.
-
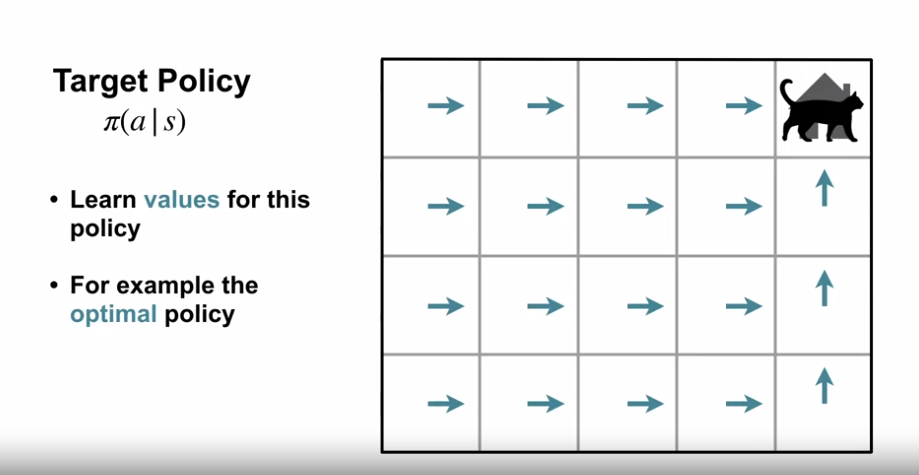
대상정책(target policy) : 에이전트가 개선해나아가며 최종적으로 획득하길 원하는 정책 + 에이전트가 학습할 가치 함수는 대상정책(target policy) 를 기반으로 함.

- 행동정책(behavior policy) : 에이전트가 행동을 선택하는 기준이 되는 정책
- Off-Policy 를 사용하는 이유
- 지속 탐색의 또다른 전략을 제공하기 때문
- 대상정책을 따라 학습하게 되면, 전체 상태가 아닌 소수의 상태만을 탐색하게 된다.
- Off-policy 에 대한 몇가지 유효한 어플리케이션이 존재함 (참고용 자료)
- learning from demonstartion
- 따라하기 학습
- 전문가의 행동을 따라하거나 전문가가 제공한 상태-행동 쌍 데이터를 이용하여 학습을 진행
- 초기에 정확한 행동을 배우기 위해 유용함
- 전문ㅏ의 경험을 통해 학습 과정을 가속화, 좋은 품질의 행동을 습득
- parallel learning
- 여러 에이전트가 동시에 병렬로 학습을 수행하는 방법 (여러 에이전트가 동시에 다른 환경 또는 다른 부분 문제를 처리)
- 학습 속도를 높이고 효율성을 향상시키는 데 도움이 됨
- 다양한 경험을 공유하고 전체 학습 성능을 향상
- 분산 시스템에서 사용되는 경우가 많으며, 학습 속도와 성능 향상을 위해 활용될 수 있음
- learning from demonstartion
- 지속 탐색의 또다른 전략을 제공하기 때문
- Off-Policy 의 중요 요건
- 행동정책 (behavior policy) 이 대상정책 (target policy) 을 포괄해야 함.
- 즉, $\pi (a | s) > 0$ 이면 $b(a | s ) > 0$ 이어야 한다.
- 수학적인 이유는 다음 섹션에서 살펴봄
- 직관적인 이유는 아래의 그림과 같을 경우, 우측으로 가는 행동에 대한 행동 가치를 알 수가 없기 때문
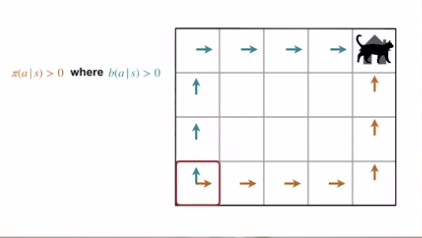
- 즉, $\pi (a | s) > 0$ 이면 $b(a | s ) > 0$ 이어야 한다.
- 행동정책 (behavior policy) 이 대상정책 (target policy) 을 포괄해야 함.
- 학습 목표
-
Importance Sampling
- 학습 목표
- 중요도 샘플링을 이용하여 다른 분포의 샘플을 통한 대상 분포도에 대한 예상 값을 추정한다.
- Importance Sampling 유도
- 개요
- Sample : $x \sim b$
- ~ : 분포에 의해 생성되는 것을 의미함.
- x : 생성된 데이터
- b : 정책
- Estimate : $\mathbb{E}_\pi [X]$
- target 정책에 의해 추정되어지는 예측값
- $b$ 에서 유도된 데이터 $x$ 이므로, 이 값을 간단히 평균내어 $\pi$ 에 대한 예측치를 구할 수 없다.
- Sample : $x \sim b$
-
기대값에 대한 정의

- $E_\pi [X] \doteq \sum_{x \in X} x \pi (x)$
- 모든 가능한 출력값 $x$ 에 대해 $\pi$ 에 따른 확률값을 곱해 합계를 구함.
- $=\sum_{x \in X} x \pi (x) \frac{b(x)}{b(x)}$
- 뒤의 $\frac{b(x)}{b(x)}$ 는 값이 1이므로 수식에 곱할 수 있다.
- $b(x)$ : b 정책 하의 관측된 결과값 $x$ 에 대한 확률값
- $=\sum_{x \in X} x \frac{\pi (x)}{b(x)} b(x)$
- 여기에서 $\frac{\pi (x)}{b(x)}$ 를 Importance Sampling Ratio 라고 한다.
- 우리는 보통 Importance Sampling Ratio 를 $\rho (x)$ 로 표기한다.
- 즉, $\sum_{x \in X} x \rho (x) b(x)$
- $E_\pi [X] \doteq \sum_{x \in X} x \pi (x)$
-
기대값을 $b$ 정책에 대한 식으로 치환

- 위 공식에서 유도된 $E_\pi [X] = \sum_{x \in X} x \rho (x) b(x)$
- $= E_b [X \rho (X)]$ : $\pi$ 에 대한 식을 $b$ 에 대한 식으로 치환함.

- $\mathbb{E} [X] \approx \frac{1}{n} \sum_{i=1}^n x_i$
- $\approx$ : 거의 동일
- 위 식은 몬테카를로에서 기대값을 구하는 방식으로 평균을 취한 값임.
- $\approx \frac{1}{n} \sum_{i=1}^n x_i \rho (x_i)$
- 즉, 위 식을 풀기 위해 weighted sample average 를 구하면 되는데, 이는 importance sampling ratio 를 weightings 로 사용한 수식이다.

- 우리는 식에서 $\pi$ 가 아닌 $b$ 의 분포를 이용하여 계산하고, 실제로 이 값은 sample average 를 이용해 $\pi$ 의 분포 아래 값을 구하는 식이 된다.
-
샘플링을 이용한 예측치를 구하는 예시
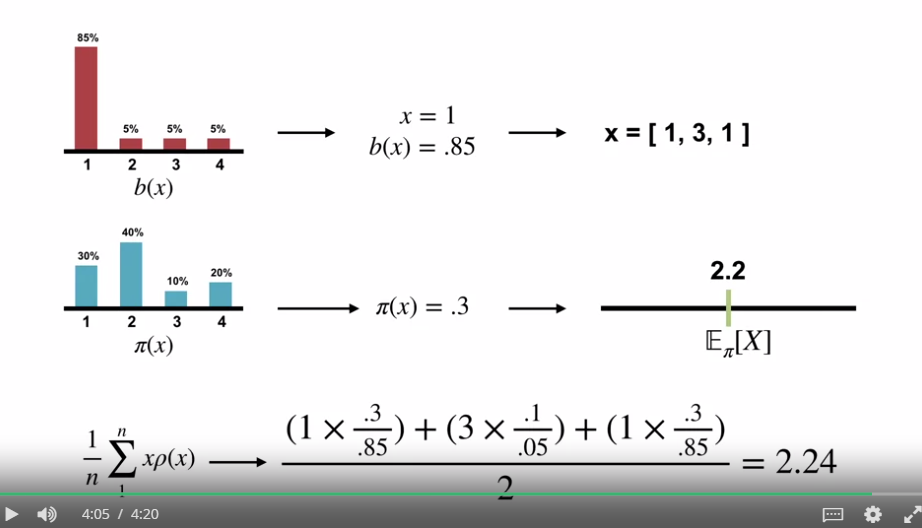
- 위의 예시는 $b$ 의 확률분포 내에서 몬테카를로 방식으로 진행했을 때 보상값이 1, 3, 1 이 나왔을 시 importance sampling ratio 를 이용해 $\pi$ 의 분포도로 치환하여 계산한 식을 의미하며 $\pi$ 의 실제 예측값인 2.2 에 가까운 근사값이 나오는 것을 볼 수 있다.
- 개요
- 학습 목표
- Off-policy Monte Carlo Prediction
- 학습 목표
- 중요도 샘플링을 이용하여 리턴값을 수정하는 방법을 이해하기
- 몬테카를로 예측 알고리즘을 변형하여 off-policy learning 에 적용하는 방법 이해하기.
-
몬테카를로 방식에 대한 복기
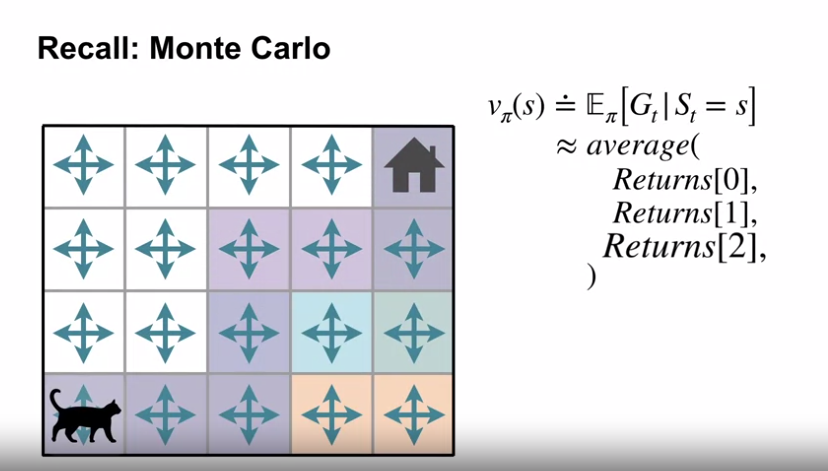
- 상태 $s$ 에서 수집된 리턴값의 평균을 구하는 방식
-
Off-Policy Monte Carlo

-
정책 $b$ 로부터 수집된 리턴값에 importance sampling ratio weight ($\rho$) 값을 곱한 값으로 평균을 구함.
- $\rho = \frac{\mathbb{P} ( \texttt{trajectory under } \pi )}{\mathbb{P} ( \texttt{trajectory under } b )}$
- 여기에서 $\rho$ 는 전체 궤적의 분포도를 수정하여 리턴값의 분포를 수정한다.
- 위 수정 방식을 이용해 $\pi$ 의 기대 리턴값을 구한다.
- $V_\pi (s) = \mathbb{E}_b [ \rho G_t | S_t = s ]$
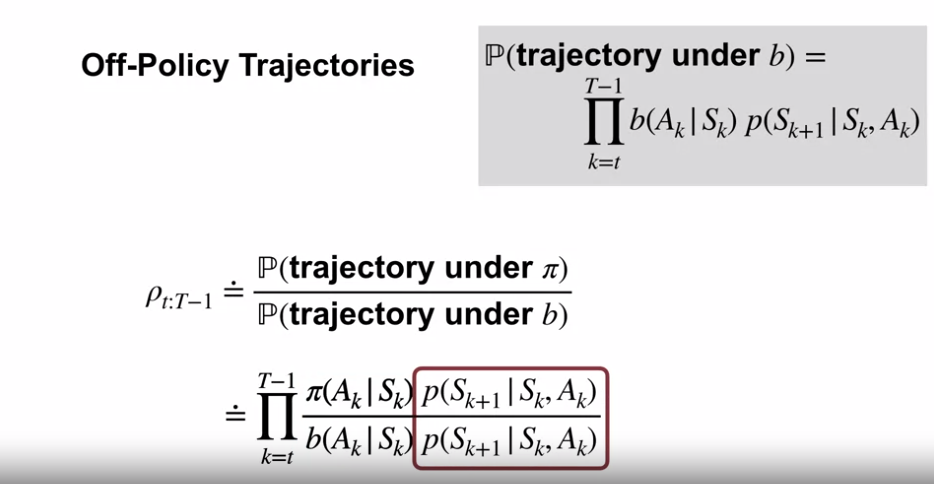
- 궤적의 확률 값은 시점 $t$ 에서 종료상태 $T$ 까지의 정책 상 행동 $a$ 의 선택 확률과 상태 $s$ 로의 전이확률 (환경역학) 값의 연속이다.
- $b(A_t | S_t) p (S_{t+1} | S_t, A_t) b(A_{t+1} | S_{t+1}) p (S_{t+2} | S_{t+1}, A_{t+1}) \cdots p (S_T | S_{T-1}, A_{T-1} )$
- 위의 식을 $\Pi_{k=t}^{T-1} b(A_k | S_k) p (S_{k+1} | S_k, A_k)$ 로 표기할 수 있다.
- 위의 식에서 환경역학 $p$ 는 동일한 값이기에 상쇄 (약분) 된다.
- 위의 식에서 남은 앞 부분은 importance sampling ratio 인 $\rho$ 이다.
- $\rho_{t:T-1} \doteq \Pi_{k=t}^{T-1} \frac {\pi (A_k | S_k)} {b (A_k | S_k)}$
- Off-Policy Value : $E_b [ \rho_{t:T-1} G_t | S_t = s] = v_\pi (s)$
-
-
Off-Policy Monte Carlo 의 구현
-
Off-policy every-visit MC

- 에피소드를 생성할 때 $\pi$ 가 아닌 $b$ 를 통해 생성한다.
- 에피소드의 리턴 값이 $G \gets \gamma G + R_{t+1}$ 이 아닌 $G \gets \gamma W G + R_{t+1}$ 로 계산된다.
- $W \gets W \frac {\pi (A_t | S_t)}{b (A_t | S_t)}$ 로 매 스텝마다 누적곱이 된다.
-
$\rho_{t:T-1}$ 의 증분계산

- 몬테카를로 알고리즘 루프가 마지막 타임스텝에서부터 거꾸로 계산을 누적하는 방식이므로, $\rho$ 의 계산 또한 동일하다.
- 위의 식과 같이 이전 단계의 값의 누적 곱을 구하는 방식이기에, 이전 단계의 모든 $\rho$ 값을 따로 저장할 필요가 없다.
-
- 학습 목표
- Emma Brunskill - Batch Reinforcement Learning
- 배치 강화학습의 개요
- 현재 강화학습의 놀라운 성공에 대해 생각해보면 로봇 공학이나 게임플에이와 같은 영역이며, 시뮬레이터에서 액세스 할 수 있는 케이스임
- 에이전트가 오랫동안 학습에 실패하더라도 결국 학습하게 됨.
- 반대로 사람과 상호작용하는 영역의 경우 사람들이 학습하거나 행동하는 방식에 대한 훌륭한 시뮬레이터를 얻을 수 없음
- 실제 데이터에 의존해야 함 (실제 인간과 상호작용 하는 것과 관련이 있기에 어려운 일임)
- 에이전트가 학습해야 하는 데이터의 양을 최소화하기 위한 기술과 학습량의 근본적인 한계는 무엇일까?
- 실 생활 데이터의 활용 어려움
- 실제 행하지 않은 행동의 결과 추론 문제
- 과거에 행했던 하나의 행동이 아닌 일련의 행동에 대한 조합 가능성
- 실 생활 데이터의 활용 가능성
- 특정한 행동순서로 진행하는 것의 결과값을 알고 싶을 때, 데이터가 10만건이라면 이 중 해당 행동순서를 가지는 경우는 100건이 될 수 있다.
- 중요도 샘플링의 문제점
- 중요도 샘플링은 편향되지 않은 추정량을 제공하지만 일반적으로 분산이 매우 높을 수 있음
- 즉, 데이터가 많지 않거나 에피소드가 길면 열악한 근사값을 구할 확률이 큼
- 중요도 샘플링은 편향되지 않은 추정량을 제공하지만 일반적으로 분산이 매우 높을 수 있음
- 중요도 샘플링의 대안 : MDP 의 Parametric Models
- 상태 전이확률과 보상 함수를 파라미터화한 모델
- 파라미터를 사용하여 상태 전이 확률과 보상함수를 추정하거나 근사하는 방식으로 동작
- 실제 환경의 동작을 정확히 모델링하지 않고도 예측과 학습이 수행 가능, 복잡한 환경에서도 효율적인 학습을 할 수 있음.
- 하지만 실제 환경과 다름 - 편향을 가질 수 있음
- 그러나 약간의 편향에 대한 대가로 낮은 분산을 가질 수 있음
- 상태 전이확률과 보상 함수를 파라미터화한 모델
- Doubly Robust Estimator 방법
- 이 방법은 오프-폴리시(Off-Policy) 학습에서 사용되며, 동일한 데이터를 사용하여 가치 함수를 추정하는 데에 효과적
- Doubly Robust Estimators의 핵심 개념은 두 가지 보정 요소를 조합하는 것
- 가치 함수 추정에 사용되는 모델 또는 추정기(estimator) : Parametric Models
- 가치 함수 추정에서 발생하는 편향을 보정하는 가중치 : Importance Sampling
- 첫 번째 방법은 모델 또는 추정기를 사용하여 행동 가치 함수 또는 상태 가치 함수를 추정하는 것. 이 추정은 일부 편향을 가질 수 있지만, 적은 데이터에서도 추정이 가능.
- 두 번째 방법은 경험 데이터를 사용하여 행동 가치 함수 또는 상태 가치 함수를 보정하는 것. 이 보정은 가중치를 사용하여 편향을 보정하는 것으로, 정책 평가의 불일치 문제를 해결하는 데 도움이 됨.
- 배치 강화학습의 개요
Chapter Summary
- 몬테카를로 방식의 장점
- 본 장의 몬테카를로 방식 : 샘플 에피소드의 형태에서의 경험으로 가치함수와 최적의 정책을 학습
- 환경 역학의 모델 없이, 환경과의 상호작용에서 직접 최적의 정책을 학습함.
- 시뮬레이션 또는 샘플 모델과 함께 사용할 수 있음.
- 많은 응용프로그램의 경우 DP 방식에서 요구하는 전환 확률의 명시적 모델을 구성하는 것은 어렵지만, 샘플 에피소드를 시뮬레이션 하는 것은 쉬움.
- 몬테카를로 방식을 상태 중 작은 하위 집합에 집중시킬 수 있다.
- 나머지 상태 집합을 정확하게 평가하는 데 비용을 들이지 않고 특별한 관심 영역을 정확히 평가 가능 (8장에서 살펴볼 내용)
- Markov 속성 위반으로 인한 피해가 적음 (이후에 다룰 내용)
- 이는 후속 상태의 가치 추정치를 기반으로 가치 추정치를 업데이트 하지 않기 때문 (부트스트랩을 하지 않기 때문)
- 몬테카를로의 제어 방법 설계
- 이 장에서는 일반화된 정책 반복 (Generalized Policy Iteration, GPI) 의 전체 스키마를 따랐음.
- GPI는 정책 평가 및 정책 개선의 상호 작용 프로세스를 포함함.
- 몬테카를로 방식은 정책 평가 프로세스를 대체함
- 모델을 사용하여 각 상태의 가치를 계산하는 대신, 상태에서 시작되는 많은 샘플의 리턴값 평균을 구함.
- 제어 방법에서 행동가치함수를 근사화 하는데 집중함. (환경의 전환 역학 모델을 요구하지 않고 정책을 개선하는데 사용 가능)
- 이 장에서는 일반화된 정책 반복 (Generalized Policy Iteration, GPI) 의 전체 스키마를 따랐음.
- 충분한 탐색을 유지하기 위한 몬테카를로 제어 방법의 문제
- 현재 최선이라고 추정되는 행동만을 선택하는 것으로는 다른 행동을 선택했을 때의 리턴값을 알 수 없고 실제로 더 나은 조치를 학습할 수 없게 됨.
- 한가지 접근 방식은 에피소드가 모든 가능성을 다루기 위해 무작위로 선택된 상태-행동 쌍으로 시작한다고 가정하여 이 문제를 무시하는 것
- 탐색 시작은 시뮬레이션된 에피소드가 있는 응용프로그램에서 사용될 수 있지만, 실제 경험에서 학습할 가능성은 낮음.
- On-Policy 방식
- 에이전트는 항상 탐색하고, 탐색이 포함된 최상의 정책을 찾으려고 노력함.
- Off-Policy 방식
- 에이전트는 탐색하지만 탐색 정책과 관련이 없을 수 있는 결정론적 최적 정책을 학습함.
- 중요도 샘플링의 일부 형태를 기반으로 함.
- 두 정책에서 관찰된 행동을 취할 확률의 비율로 구해, 리턴값에 가중치를 부여하여 행동정책에서 대상정책으로 기대치를 변환함.
- 일반 중요도 샘플링 : 가중 수익율의 단순 평균을 사용
- 편향되지 않은 추정치를 생성하지만 분산이 더 크고 무한할 수 있음
- 가중 중요도 샘플링 : 가중 평균을 사용
- 유한한 분산을 가짐
- 에이전트는 탐색하지만 탐색 정책과 관련이 없을 수 있는 결정론적 최적 정책을 학습함.
- 개념적 단순성에도 불구하고 예측 및 제어 모두에 대한 정책 외 몬테카를로 방법은 여전히 불안정하며 지속적인 연구 대상임
- 몬테카를로 방식과 DP 방식의 차이점
- 샘플 경험을 기반으로 작동하므로 모델 없이 직접 학습에 사용할 수 있음
- 부트스트랩을 수행하지 않음 (다른 가치 추정치를 기반으로 가치 추정치를 업데이트하지 않음)
- 다음 장에서는 몬테카를로 방법과 같이 경험에서 배우는 방법과 DP 방법과 같은 부트스트랩 방법을 고려함.
댓글남기기