
Prediction and Control with Function Approximation - 02. Week 2. Constructing Features for Prediction
관련 자료 (RLbook Pages 204-210, 215-222, 223-228)
Linear Methods
- Linear Methods 에 대하여
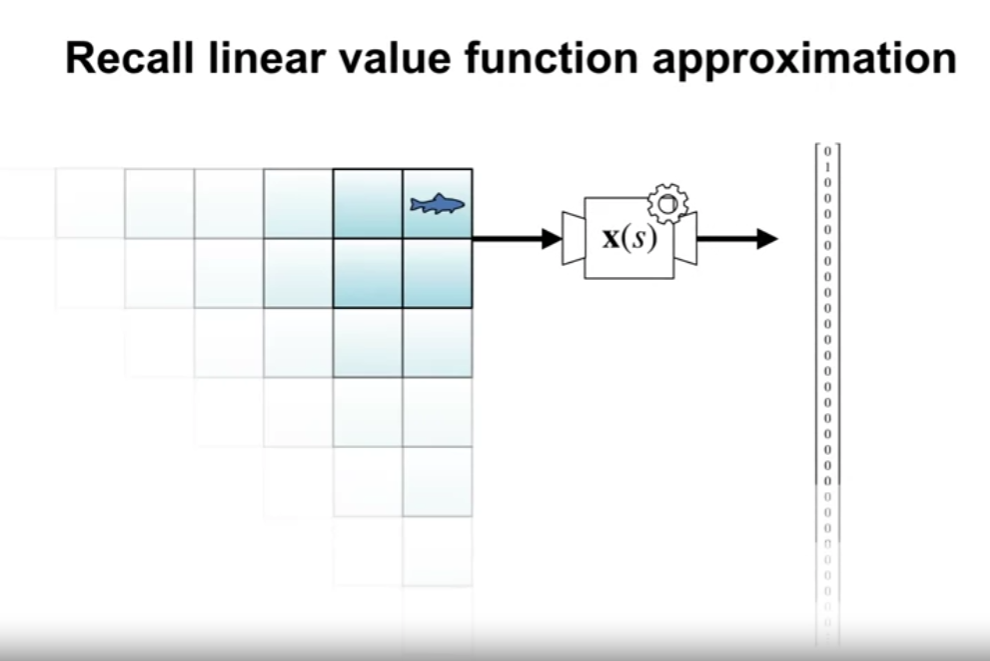
- 근사함수 $\hat{v}(\cdot ,w)$ 중 가장 중요하고 특수한 케이스는 선형함수임.
- 실제 값을 가진, $\textbf{w}$ 와 동일한 요소 수를 가진 벡터 $\textbf{x} (s) \doteq (x_1(s),x_2(s),\cdots , x_d(s))^{\top}$ 와 대응한다.
-
상태-가치 함수의 선형 근사 방식은 $\textbf{w}$ 와 $\textbf{x} (s)$ 의 내적으로 이루어 진다.
$\hat{v}(s,\textbf{w}) \doteq \textbf{w}^{\top} \textbf{x} (s) \doteq \sum_{i=1}^d w_i x_i (s)$
- Features 에 대하여
- $\textbf{x} (s)$ 는 상태 s 를 표현하는 feature vector 라 한다.
- 여기서 feature 는 위 함수 자체라 생각하고, 상태 s 에 대한 이 함수 값을 s 의 feature 라 일컷는다.
- 선형함수에서 feature 는 기저함수 (basis function) 이 되는데 이는 근사 함수의 선형 기저를 형성하기 때문이다.
- 기저함수는 함수 공간 내에서 다양한 형태의 함수를 생성하는데 사용됨.
- 예를 들어, feature 의 요소 중 하나가 실제 값이 아닌 가공된 비선형 값일 경우, 선형함수의 한계를 극복하고 더 복잡한 표현이 가능하게 된다.
- 이러한 feature 들을 선정하는 방법에는 다양한 방법이 있다.
- 선형 근사함수에 대한 SGD 업데이트가 가지는 장점
-
가중치 $\textbf{w}$ 에 대한 가치 근사함수의 미분값
$\nabla \hat{v} (s,\textbf{w}) = \textbf{x} (s)$
-
따라서 SGD 업데이트 는 아래의 간단한 형태로 표현된다.
$w_{t+1} \doteq w_t + \alpha [U_t - \hat{v}(S_t, w_t) ] x(S_t)$
-
- Linear SGD 에 대해
- 위의 간단한 식 때문에, 수학적 분석에서 linear SGD 는 가장 선호되는 방식이다.
- 모든 종류의 학습 시스템에서 대부분의 유용한 수렴의 결과는 선형 혹은 단순한 함수 근사 방식 덕분이다.
- 특히 선형의 경우 하나의 최적값을 가진다.
- 또한 이 로컬/전역 최적점으로 수렴하는 것이 자동으로 보장된다.
- 예를 들어 이전 장의 gradient Monte Carlo 알고리즘은 $\alpha$ 값이 선형 가치근사 함수 하에 $\overline{VE}$ 의 전역 최적점으로 수렴한다.
- The semi-gradient TD(0) under linear function approximation
- semi-gradient TD(0) 또한 선형 근사함수 하에 수렴한다. 그러나 이는 Linear SGD 와 다르게 몇 가지 이론이 더 필요하다.
- 또한 가중치 벡터도 전역 최적점으로 수렴하는 것이 아닌 가까운 지역 최적점으로 수렴하게 된다.
- 이러한 케이스는 연속적인 경우에 유용하다.
-
아래는 업데이트 식이다.
$w_{t+1} \doteq w_t + \alpha (R_{t+1} + \gamma w_t^{\top} x_{t+1} - w_t^{\top} x_t) x_t$ $= w_t + \alpha (R_{t+1}x_t - x_t(x_t - \gamma x_{t+1})^{\top} w_t)$
- 여기에서 $x_t = x(S_t)$ 이다.
-
만약 시스템이 안정화 되었을 때, 주어진 $w_t$ 에 대해, 다음 스텝의 가중치 벡터는 아래와 같이 표현할 수 있다. $\mathbb{E} [w_{t+1}|w_t] = w_t + \alpha (b-Aw_t)$ $b \doteq \mathbb{E} [R_{t+1}x_t ] \in \mathbb{R}^d$ and $A \doteq \mathbb{E} [x_t(x_t - \gamma x_{t+1})^{\top} ] \in \mathbb{R}^d x \mathbb{R}^d$
-
위 식에 따라, 만약 시스템이 수렴한다면, 가중치 벡터는 반드시 아래의 $w_{TD}$ 로 수렴하게 된다. $b-Aw_{TD} = 0$ $\Rightarrow b = Aw_{TD}$ $\Rightarrow w_{TD} \doteq A^{-1}b$
- 위 값을 TD fixed point 라고 한다.
- linear semi-gradient TD(0) 는 이 지점으로 수렴하게 된다.
-
TD fixed point 에서 $\overline{VE}$ 는 가능한 최소 에러값의 확장된 경계선 내에 있음이 보장된다. (연속적인 케이스에서)
$\overline{VE}(w_{TD}) \leq \frac{1}{1-\gamma} \min_w \overline{VE} (w)$
- $\gamma$ 값이 흔히 1과 가까운 경우가 많으므로, 이 확장계수는 상당히 커질 수 있으며 TD 의 점근적 성능에 영향을 줄 수 있다.
- 반면에 TD 방식은 몬테카를로 방식과 비교하여 분산이 크게 감소되는 경우가 많으며, 학습속도도 빠르다.
- 어떤 방식이 더 나을 지는 근사와 문제, 학습이 얼마나 지속되는지에 따라 다르다.
- 타 방식에 대한 건
- 타 on-policy bootstrapping 방식에도 위 TD fixed point 와 에러 경계선이 적용된다.
- linear semi-gradient DP
- One-step semi-gradient action-value methods (Semi-gradient Sarsa(0))
- 이러한 수렴 결과의 한계는 상태가 on-policy distribution 에 따라 업데이트 된다는 점이다.
- 그러나, 선형 함수 근사를 사용하여 강화학습을 할 때, 안정적으로 수렴하려면 정책에 따라 상태를 업데이트하는 분포가 필요하며, 다른 분포에서는 부트스트래핑이 불안정할 수 있음
- 타 on-policy bootstrapping 방식에도 위 TD fixed point 와 에러 경계선이 적용된다.
- Bootstrapping on the 1000-state Random Walk
- 이전 예제에 쓰였던 1000-state Random Walk 를 동일한 방식으로 10개의 상태 그룹으로 묶어 (State aggregation) 진행한 결과
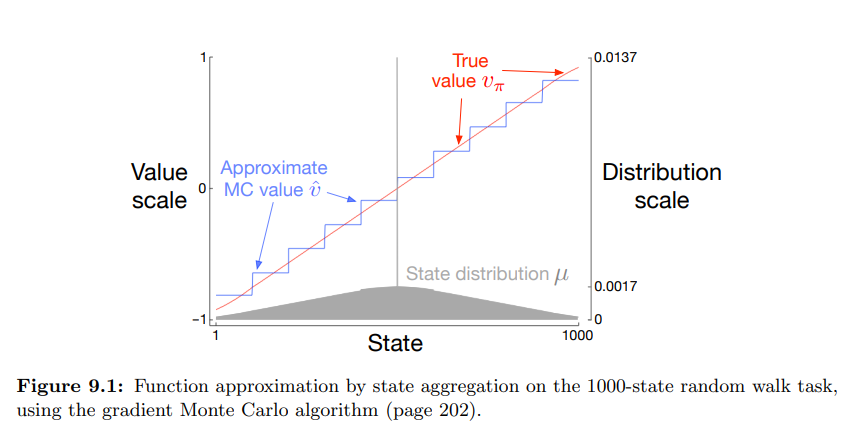
- 위 이미지는 문제를 gradient MC 방식으로 진행한 결과값
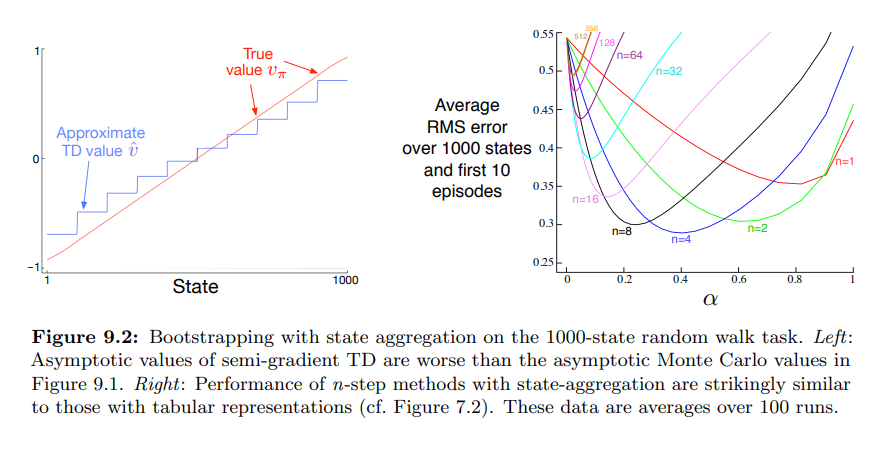
- 위 이미지는 문제를 semi-gradient TD 방식으로 진행한 결과값
- 위 결과와 같이 TD approximation 은 Monte Carlo approximation 보다 참 값에서 거리가 멀다.
- 그럼에도, TD 는 학습률에서 큰 잠재적 장점을 가지고 있고,
- 위 오른쪽 그림에서처럼, 일반화된 Monte Carlo 방식을 n-step TD 를 이용해 진행할 수 있다.
- n-step semi-gradient TD
- semi-gradient n-step TD 는 tabular n-step TD 알고리즘에 function approximation 을 적용한 자연스러운 확장이다.
- Pseudocode 는 아래와 같다.

Feature Construction for Linear Methods
- 개요
- Linear Methods 는 수렴 보장, 데이터와 계산의 효율성 등의 이점이 있다.
- 이와 더불어 어떠한 상태의 특성을 선택하는지가 매우 중요하다.
- 이 일은 강화학습 시스템에 사전 도메인 지식을 추가하는 주요한 방법이다.
- Linear Form 의 한계는, 각각의 feature 가 서로 간섭할 수 없다는 점이다.
- pole-balancing 작업에서 각속도와 각도는 상호의 값에 따라 좋은 상태일 수도, 나쁜 상태일 수도 있다.
- 선형 가치함수는 각속도와 각도를 각각 상태로 입력받은 경우, 이러한 부분을 표현할 수 없다.
- 만약 이런 부분의 고려가 필요하다면, 관련된 값을 feature 로서 제공해 주어야 한다.
- 위를 가능하게 하는 다양한 방식에 대해 알아본다.
- Polynomials
- 다양한 문제들은 숫자로 표현된다.
- 이러한 문제들은 강화학습에서의 함수 근사가 interpolation (보간) 과 regression (회귀) 의 작업과 유사한 작업을 수행한다.
- interpolation (보간) : 주어진 데이터 사이의 값을 추정
- regression (회귀) : 독립 변수(입력 변수)와 종속 변수(출력 변수) 간의 관계를 모델링
- Polynomials (다항식) 은 보간과 회귀에서 보편적으로 사용되는 특성으로, 강화학습에도 적용이 가능하다.
- 여기에서 논의하는 다항식 특성은 여기에서 논의하는 강화학습에서의 다른 형태의 특성과 같이 잘 적용되지는 않으나, 간단하고 익숙한 방식이다. $\textbf{x}(s) = (s_1,s_2)^{\top}$ $\textbf{x}(s) = (1, s_1, s_1 s_2, s_1^2, s_2^2, s_1 s_2^2, s_1^2 s_2, s_1^2 s_2^2)^{\top}$
- 기존 $s_1, s_2$ 만 features 로 있을 경우, 두 feature 간 상호작용이 불가하며, 두 feature 의 값이 0일 경우, 근사 가치 또한 0이 된다.
- 하단의 features 는 이러한 한계를 극복한 features 이나, 원 feature 가 늘어날 수록 생성하는 feature 의 갯수가 지수적으로 늘어난다.
- Fourier Basis
- Fourier 기저 함수는 주기적인 함수를 표현하는 데 사용되는 수학적인 개념이다.
- 주기적인 신호를 주파수 도메인에서 다양한 주파수 성분으로 분해하여 표현
- Fourier 기저 함수는 코사인 함수와 사인 함수의 선형 조합으로 이루어져 있음.
- 여기에서는 주어진 상태를 근사하기 위해 Fourier Basis 를 사용하여 가치함수를 선형 함수로 근사하는데 활용된다.
- 값이 가지는 계절성이나 주기성을 포착, 이를 Fourier Basis 를 이용하여 가치 함수를 생성하고, Fourier Basis 의 계수를 학습한다.
- 이 때 함수의 구조는 선형으로 나타나게 된다.
- 또한 Fourier 기저 함수는 상태 공간의 차원을 줄이는 데에도 사용될 수 있다.
- Fourier 기저 함수는 주기적인 함수를 표현하는 데 사용되는 수학적인 개념이다.
-
Coarse Coding
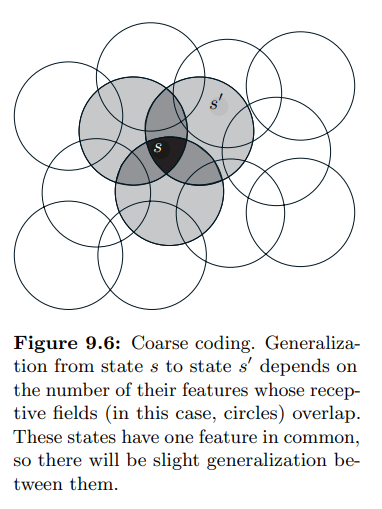
- 예를 들어 2차원의 상태 셋이 있을 경우, 위 그림과 같이 해당 차원에 특정 영역을 만들고 해당 영역에 해당할 경우 1, 그렇지 않을 경우 0을 부여할 수 있다.
- 1, 0 으로 표현되는 상태 특성을 binary feature 라 한다.
- 위와 같은 형태의 상태 feature 를 나타내는 방식 (비록 형태가 원이 아니고, 값이 binary 가 아닐 지라도) 을 coarse coding 이라 한다.
- 각각의 영역에 대항하는 하나의 가중치가 있다고 하였을 때, 특정 지점의 상태에 대한 학습을 진행할 경우 이 상태를 포함한 영역의 모든 가중치 값이 영향을 받게 된다.
- 즉, 이 영역의 shape 가 일반화에 대한 내용을 결정하게 된다.
- 수용 필드가 큰 feature 는 광범위한 일반화를 제공하지만, 미세한 차별을 만들 수 없다.
- 그러나 다행이도 정밀한 식별은 전체 특징 수에 의해 더 많이 제어된다.
-
Figure 9.8 : 초기 일반화에 대한 특징 너비의 강력한 효과(첫 번째 행) 및 점근적 정확도에 대한 약한 효과(마지막 행)의 예
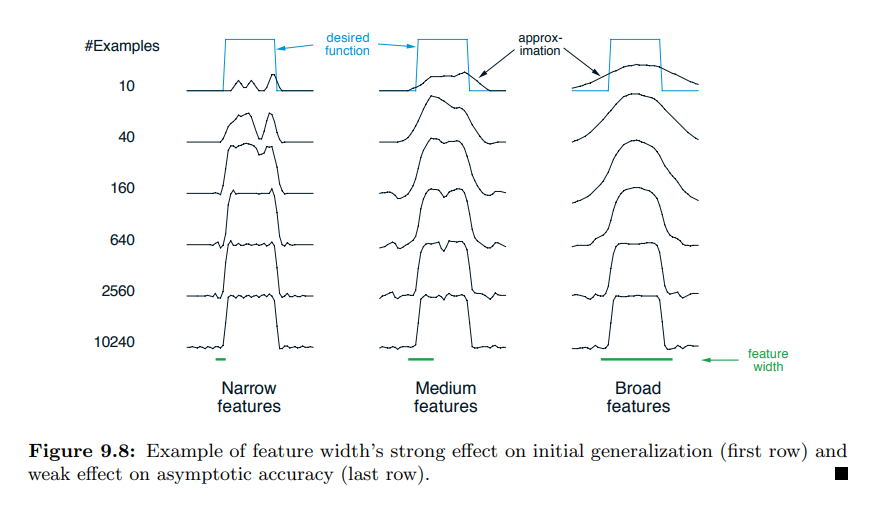
- 예를 들어 2차원의 상태 셋이 있을 경우, 위 그림과 같이 해당 차원에 특정 영역을 만들고 해당 영역에 해당할 경우 1, 그렇지 않을 경우 0을 부여할 수 있다.
-
Tile Coding
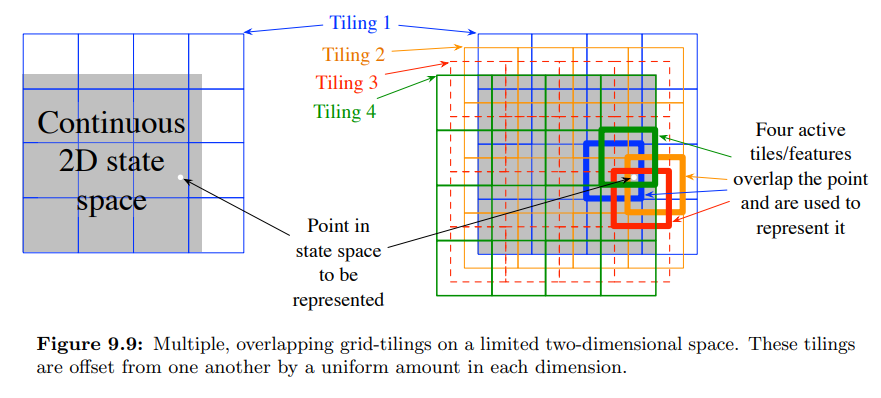
- Tile coding 은 coarse coding 의 한 종류로, 연속 공간에서 유연하고 계산에 용이하도록 구역을 나누는 것이다.
- 위의 그림과 같이 구역을 나누는데, 만약 하나의 Tiling 을 사용한다면 이것은 state aggregation 의 케이스에 해당한다.
- 위의 그림에서 feature vector $\textbf{x}(s)$ 는 각 타일별로 1개의 요소를 가지게 되며 총 $4x4x4=64$ 개의 요소를 가지게 된다.
- 위의 한 지점의 경우 64개 중 4개의 요소가 1이 되며 나머지는 0이 된다.
- 또한 Tile coding이 가지는 이점으로, 각 tiling 별로 상태가 속하는 partition은 하나가 되며, 이러한 특성으로 step-size parameter 를 설정하기 쉽다.
- 1 Tiling 에 $\alpha = 0.0001$ 이라면 50 Tiling 에 $\alpha = 0.0001/50$
- 값이 0과 1로 이루어져 있어 계산에 이점이 있다.
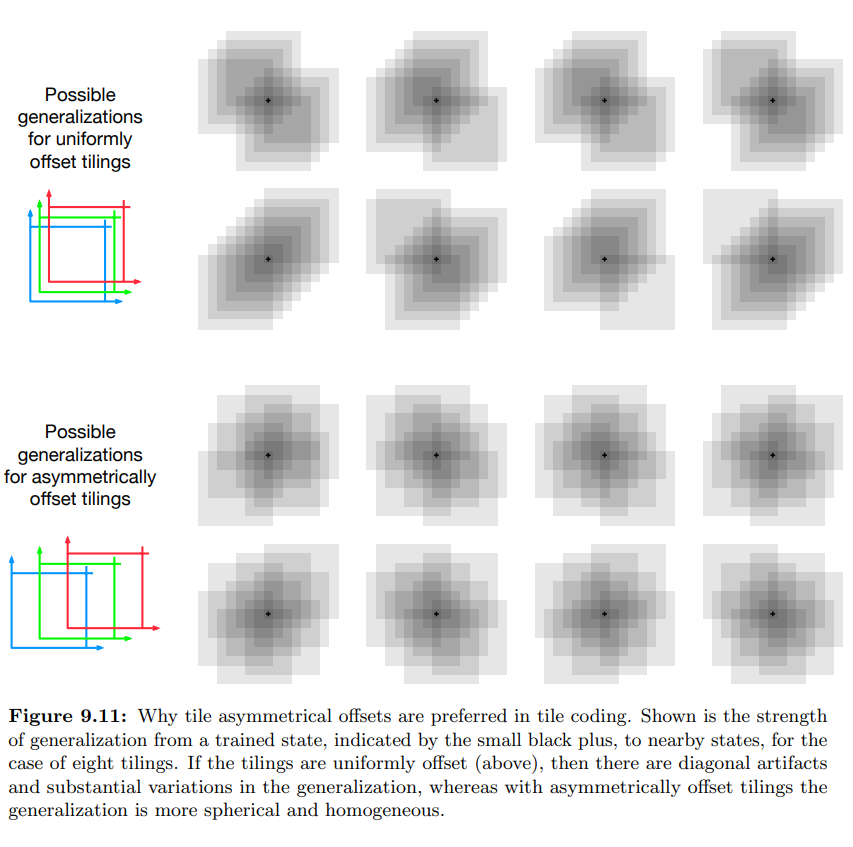
- tiling 을 할 때, uniform 한 것 보다 asymmetric 한 것이 좋다. (위의 이미지는 인접점에 대한 예시)
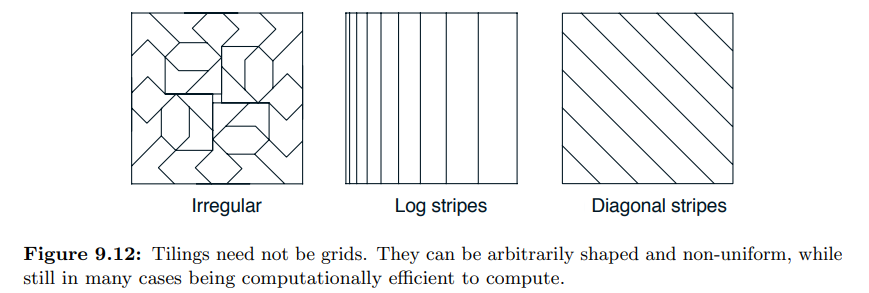
- tiling 은 반드시 grid 여야 할 필요는 없다.
- Hashing 기법을 사용하여 큰 타일을 훨씬 작은 타일 세트로 일관되게 의사 난수로 축소
- 해싱은 상태 공간 전체에 무작위로 퍼져 있지만 여전히 완전한 파티션을 형성하는 연속되지 않고 분리된 영역으로 구성된 타일을 생성한다.
- 예를 들어 하나의 타일은 오른쪽에 표시된 4개의 하위 타일로 구성될 수 있다.
- 해싱을 통해 메모리 요구 사항은 성능 손실이 거의 없이 크게 감소되는 경우가 많다.
- 이는 상태 공간의 작은 부분에만 고해상도가 필요하기 때문에 가능
- 즉, 해싱은 메모리 요구 사항이 차원의 수에 따라 기하급수적으로 늘어날 필요가 없고, 작업의 실제 요구 사항과 일치하면 된다는 점에서 차원의 저주에서 우리를 해방시킨다.
- Radial Basis Function
- RBF 는 coarse coding 의 일반화의 종류로 0과 1로 표현하는 것이 아닌 0에서부터 1까지의 값으로 표현한다.
- 중심으로부터 떨어진 거리의 표준값
- RBF 방법은 미분이 가능한 근사 함수를 원할하게 생성한다는 장점이 있으나 잘 쓰이지 않는다.
- 상당한 추가 계산 복잡성이 필요
- 2개 이상의 차원 상태에서는 성능이 저하됨
- 가장자리에서의 잘 제어된 활성화를 얻는 것이 어려움.
-
Nonlinear Function Approximation : Artificial Neural Networks
- Artifical neural networks (ANNs) 은 비선형 함수 근사에 많이 쓰인다.
- ANN 은 상호 연결된 유닛 (뉴런의 정보를 가지고 있는) 들로 신경망 시스템의 주 요소이다.
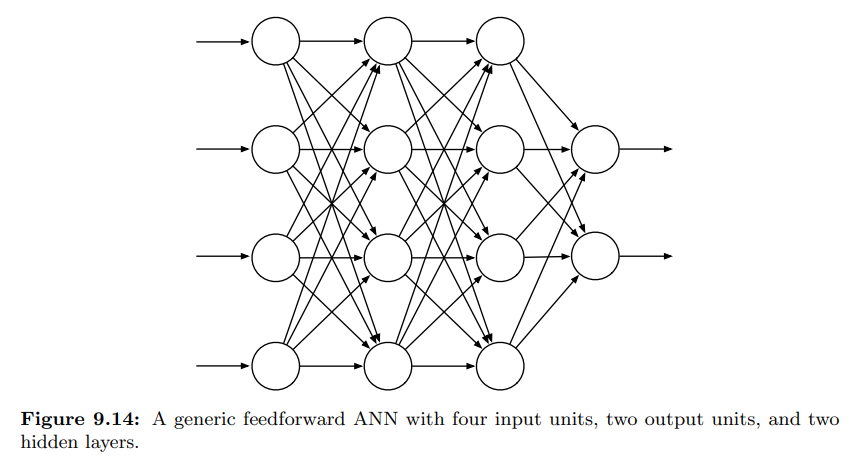
- 위의 이미지는 일반적 feedforward (순전파) ANN 을 다룬다.
- 네트워크 상 순환고리가 없으며, 유닛의 출력값이 입력값에 영향을 영향을 주는 path 가 없는 경우
- input layer, output layer, hidden layer 로 구성됨.
- 각각의 연결에 실제 값인 가중치가 부여되어 있음.
- 가중치는 실제 신경망 시냅스 연결 효율성과 대략적으로 일치함.
- ANN 이 연결에 하나라도 루프가 있다면, 이것은 feedforward ANN 이 아닌 recurrent ANN 이 된다.
- 위의 원 모양 요소는 semi-linear units 으로, 입력값들과 가중치들의 합을 구한 뒤, 비선형 함수 (activation function) 을 적용하게 된다.
- S-shaped
- sigmoid (로그함수와 비슷한) : $f(x) = \frac{1}{(1+e^{-x})}$
- 비선형 정류기 : $f(x) = \max (0,x)$
- Step function : $f(x) = 1$ if $x \geq \theta$ , and 0 otherwise
- 활성화 함수의 비선형성이 필수적으로 요구된다.
- 선형 함수를 겹쳐도 또 다른 선형함수로 표현된다.
- 단일 hidden-layer 의 보편적 근사 속성에도 불구하고 경험과 이론 모두, 복잡한 함수를 근사하는 것이 필요하다는 것을 보여준다.
- ANN 에서 은닉층을 훈련시킨다는 것은 손으로 요소를 선별하는 것이 아닌 주어진 문제에 적합한 요소를 자동으로 생성한다는 것과 같다.
- ANN 은 보편적으로 확률적 경사 방식으로, 전체 네트워크의 성능을 Objective function 으로 측정하여 개선 (maximize/minimize) 시키는 것이다.
- ANN 의 가중치를 학습하는 가장 효과적인 방법은 역전파 알고리즘이다.
- 순전파는 입력값에 대한 각 유닛의 활성화를 계산
- 순전파 이후 역전파는 각 가중치의 편미분 값을 계산해낸다.
- 역전파 알고리즘은 얕은 네트워크 층 (1, 2개의 은닉층을 가진) 에서 잘 작동하나, 심층 네트워크에서는 잘 동작하지 않는다.
- $k+1$ 층의 네트워크 훈련이 $k$ 층 네트워크의 훈련보다 더 안좋은 성능을 보여준다.
- ANN 이 가지는 문제점들
- 많은 수의 가중치는 과적합의 문제를 야기한다.
- 역전파는 심층 인공신경망에서 잘 동작하지 않는다. (편미분 값이 층을 이동하며 빠르게 소실된다.)
- 학습속도가 매우 느려지거나, 수렴하지 않게 된다.
- 과적합 문제의 해결
- 과적합은 제한된 학습 데이터에서 일어나는 문제로, 온라인 강화학습 (제한된 학습 데이터셋이 아님) 에서는 덜 문제가 되는 경향이 있다.
- 그러나 효과적인 일반화는 여전히 중요한 문제이다.
- 과적합 문제는 ANN 에서 보편적이나, 특히 심층 ANN 에서 중요하다.
- 해결을 위한 방법
- Cross validation : Validation data 를 통해 성능이 떨어지기 시작하면 학습을 중단하는 방법
- Regularization : Objective function 을 변경해 근사의 복잡성을 줄이는 방법
- Weight Sharing : 차원 (Degrees of freedom) 을 줄이기 위한 가중치 간 종속성의 도입
- Dropout : 네트워크에서 유닛을 랜덤하게 제거하는 것 (드물게 발생하는 경우에 지나치게 특화되지 않도록 함)
- Deep ANN 의 훈련법
- Deep belief networks : 가장 깊은 층 부터 출력 값에 대한 비지도학습을 진행하여 가중치를 초기화한 뒤 학습하는 방법
- Batch normalization : 네트워크의 입력 변수들을 정규화
- deep residual learning : deep ANN 에서 그래디언트 소실 문제를 해결하기 위해 입력값과 출력값의 차이를 학습하여 더하는 방식으로 학습을 진행
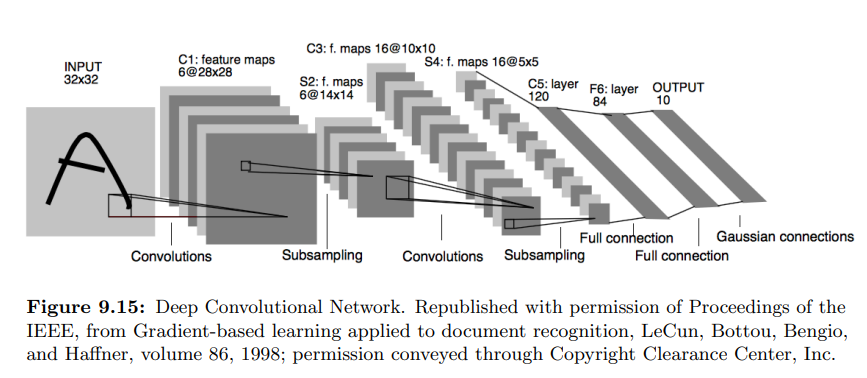
- deep convolutional network : 구조적인 특수성 덕분에 그래디언트 소실 문제가 완화되고, 네트워크가 깊어질 수록 성능이 향상될 수 있음
- 계층적인 특징을 학습, 공간적인 구조 정보의 보존
Feature Construction for Linear Methods
- 가치 측정을 위한 feature 의 선정은 강화학습 에이전트의 가장 중요한 요소 중 하나이다.
Coarse coding
- 학습목표
- 거친 코딩에 대해 설명하기
- 거친 코딩이 state aggregation 과 어떠한 연관이 있는지 설명하기
- 선형 가치함수 근사
- $v_\pi (s) \approx \hat{v}(s, \textbf{w} ) = \textbf{w}^{\top} \textbf{x} (s)$
- feature vector $\textbf{x} (s)$ 생성
- 가중치 벡터와 내적 계산
- $v_\pi (s) \approx \hat{v}(s, \textbf{w} ) = \textbf{w}^{\top} \textbf{x} (s)$
-
선형 가치함수 근사의 특수 케이스로서의 표 형식 표현 (tabular case)
- tabular case 는 선형 가치함수 근사의 특수 케이스로 위 그림과 같이 하나의 상태를 binary one-hot encoding 방식으로 표현할 수 있다.
- 하지만 상태가 많아질 경우, 위 방식은 한계가 있다.
- State Aggregation
- 2차원 상태에서의 상태값을 생각해보면, 아래 물고기는 무한한 위치에 있을 수 있고, 이것을 유한한 테이블 형태로 표현이 불가능하다.
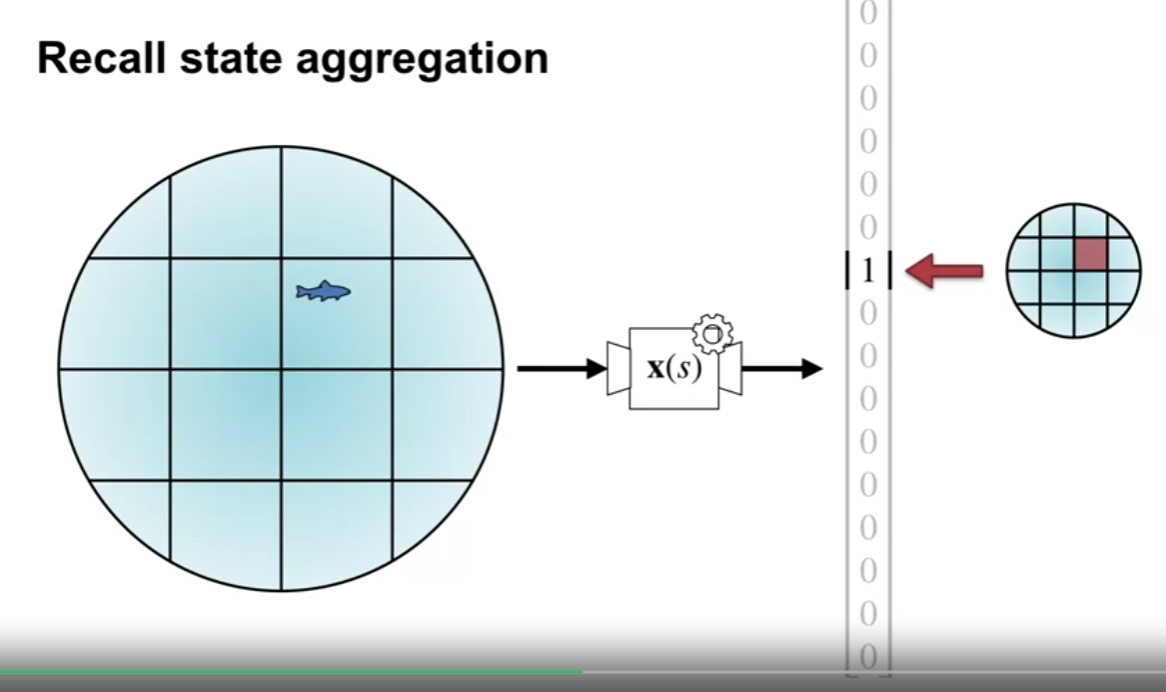
- 위 그림과 같이 그룹으로 묶어 해당 구역에서는 같은 값으로 표현한다.
- 위 구역의 모양은 반드시 그리드 형태일 필요는 없다. (불규칙적이어도 상관없음)
- 상태값이 2차원일 필요는 없음
-
Coarse coding
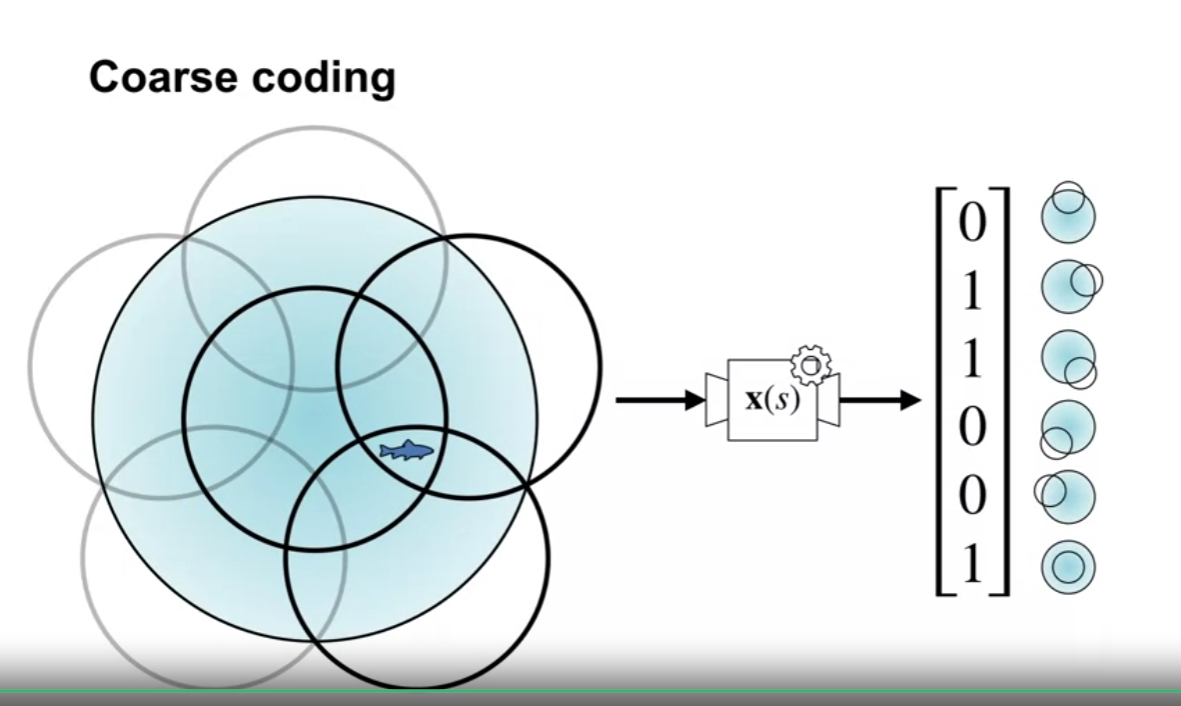
- 영역의 중복을 허용
- 각 영역에 포함되는지 안되는지를 표현
- 상태값이 2차원일 필요는 없음
- coarse coding 은 state aggreagtion 을 일반화한 표현방식이다.
Generalization Properties of Coarse Coding
- 학습목표
- coarse coding 의 파라미터가 어떻게 차별 (discrimination) 과 일반화 (generalization) 에 영향을 주는지 이해
- 위의 구분 (discrimination) 과 일반화 (generalization) 가 어떻게 학습 속도와 정확도에 영향을 주는지 이해
-
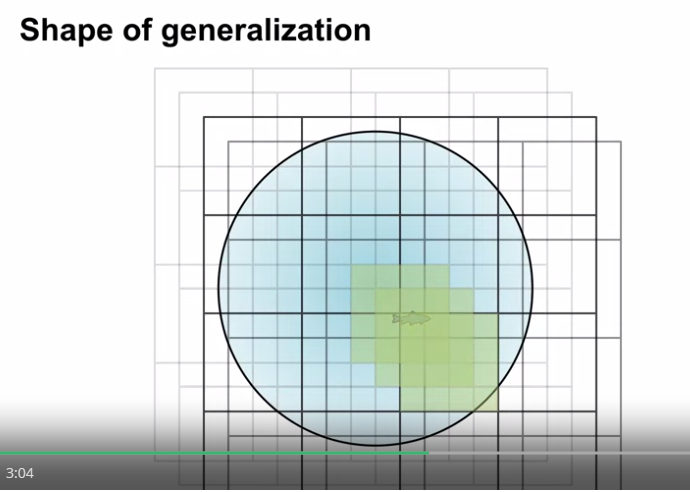
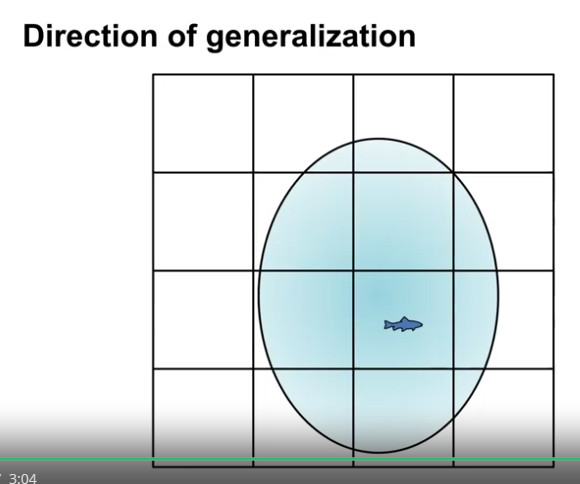
Coarse Coding 의 요소
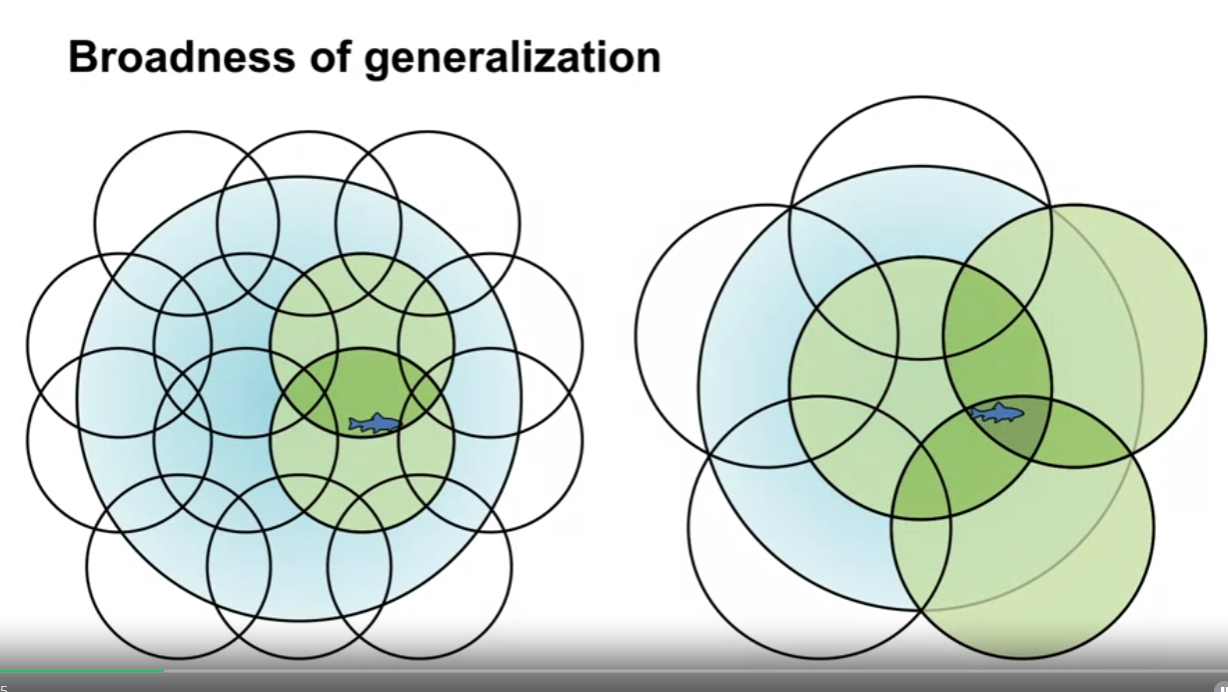
- active feature 에 대응하는 영역의 집합이 클수록 특징 표현은 더 일반화된다.
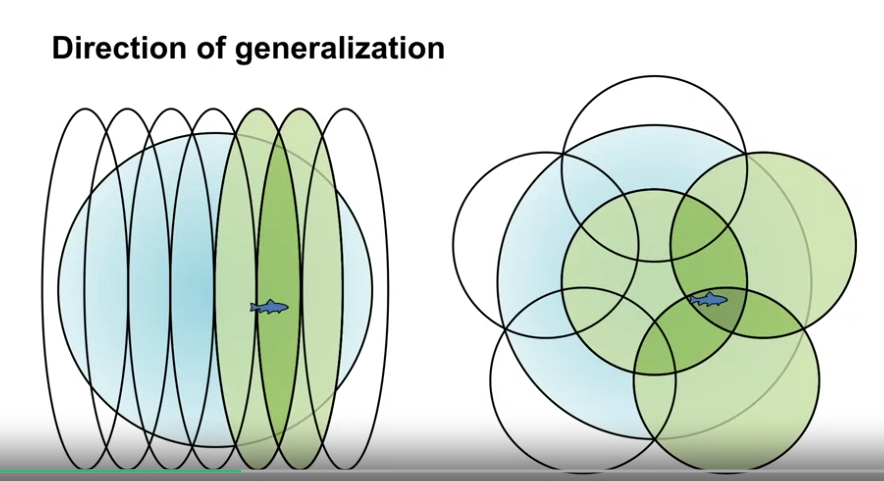
- 영역의 형태에 따라 일반화를 하는 방향이 달라진다.
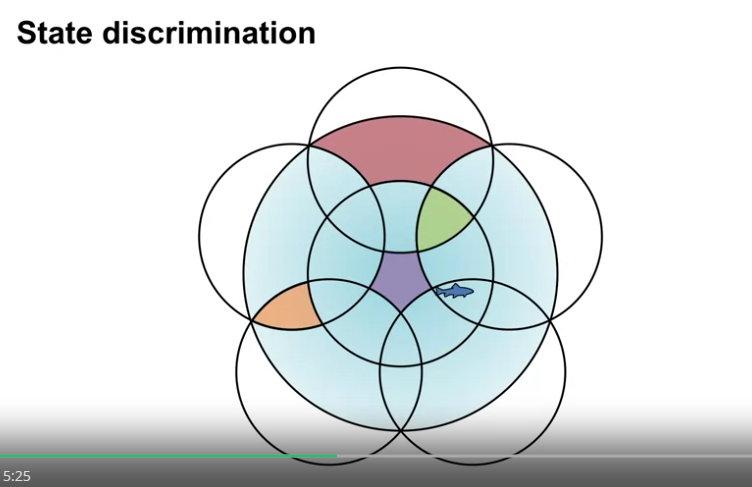
- 위의 독립된 영역의 크기가 상태 구분의 정도를 나타낸다.
- 완벽한 상태의 구분은 할 수가 없는데, 하나의 상태 값의 업데이트가 다른 상태 값 또한 업데이트 시키기 떄문
- 위의 같은 색으로 표현된 상태들은 동일한 feature vector 값을 가지게 된다.
- 즉, 위의 구역이 더 세분화 될수록 더 높은 상태의 구분도를 가지게 된다.
-
1D Example
- interval 이 짧은 경우
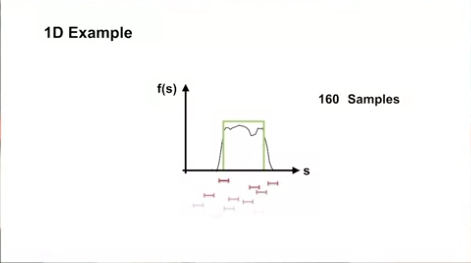
- interval 이 긴 경우
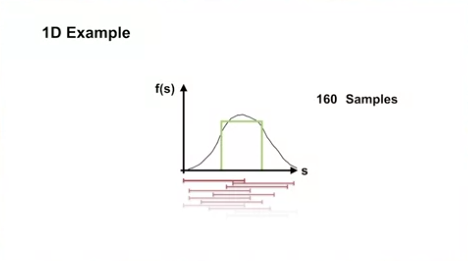
- 위의 예제에서 10240 샘플을 학습할 경우 interval 이 긴 경우가 학습속도나 결과가 더 좋았음
- 위의 예제에서는 interval 이 긴 경우가 구분과 일반화의 측면에서 더 좋은 결과를 가져왔음
Tile Coding
- 학습목표
- Tile Coding 이 어떻게 일반화와 구분을 달성할 수 있는지 설명
- Tile Coding 의 이점과 한계에 대해 이해
-
타일 코딩에 대해서
- Tile Coding 은 Coarse Coding 의 한 종류로, 그리드 (Tiling) 를 중복해서 상태 공간을 전체적으로 철저히 분할한다.
- 하나의 Tiling 은 State aggregation 과 같다.
- 위의 예제에서는 Tiling 간 동일한 offset 을 사용하여 대각의 영역이 생성되었으나, offset 이 랜덤할 경우 좀 더 구형으로 형성된다.
- 일반화에 대한 제어가 필요한 경우 상태 공간을 스케일링 하거나, 그리드의 크기를 변경시킨다.
- 타일 코딩의 이점
- 그리드가 균일 (uniform) 하다면, 어느 타일에 속해있는지 계산하기 쉽다.
- 계산 상의 이점으로, 저 차원의 환경에서 타일코딩을 이용해 선행 실험을 할 수 있다.
- 타일 코딩의 한계
- 상태 공간의 차원이 늘어날 수록, 필요한 타일의 수도 지수적으로 증가한다.
- 따라서 입력 차원을 독립적으로 처리할 수 있는지를 고려해야 하는데, 이는 문제에 따라 다르다.
Using Tile Coding in TD
- 학습목표
- Tile Coding 을 TD learning 에 적용하는 방법을 설명
- Tile Coding 표현방식에서 중요한 요소를 식별
-
Tile Coding 의 계산 상 이점

- Tile Coding 으로 표현 시, 특정 상태를 표현할 때, 적은 영역의 활성화로 표현된다.
- 이는 feature vector 가 sparse binary vector (희소 이진 벡터) 로 표현된다는 의미이다.
- 이 때, 계산은 단순히 몇몇 가중치의 합으로 표현되며 이는 행렬곱을 계산하는 것보다 훨씬 비용이 작다.
-
Tile Coding 계산의 간단한 예시
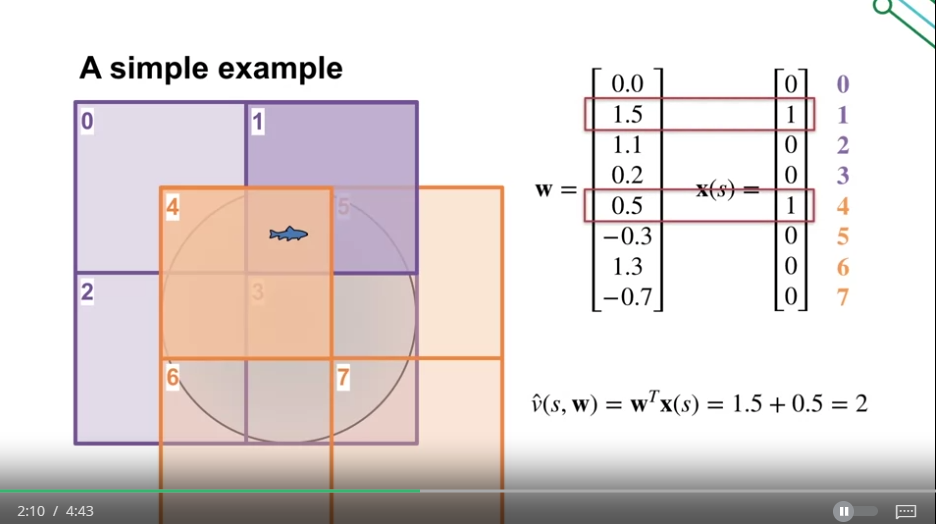
-
1000-steps random walk 문제에서 Tile coding 과 State aggregation 의 비교
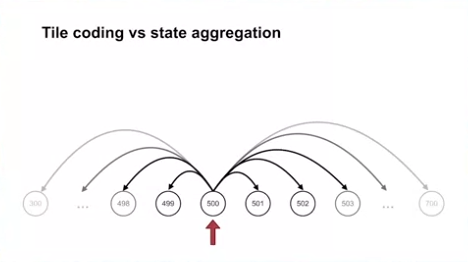
- 상태 500에서 시작하여 좌, 혹은 우로 200 스텝 범위 안으로 랜덤하게 움직일 수 있다고 가정
- 상태 1 또는 1000을 벗어나면 Terminal State 로 진입

- 상태 200개를 묶은 state aggregation 은 5개의 영역으로 표현됨
- 상태 200개를 묶은 tile coding 은 좌, 우의 미표현 영역으로 인해 6개의 영역을 생성해야 함
- 50개의 tiling 을 사용하여 학습한다고 가정
- step-size 의 경우 tile coding 은 사용된 tiling 의 수 만큼 더 나눈 값을 사용
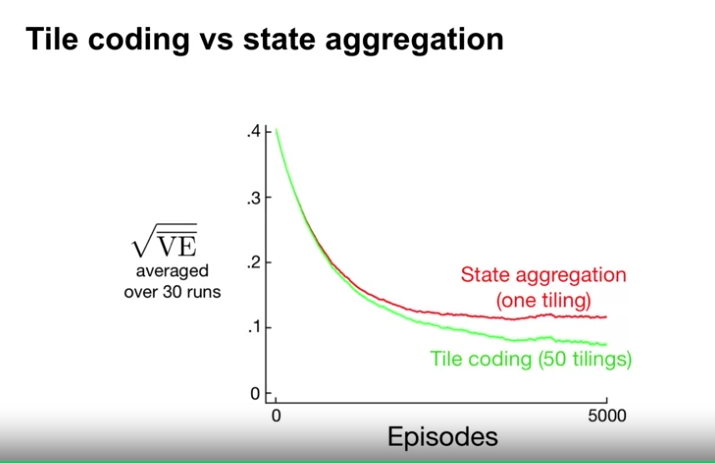
- 결과적으로 Tile coding 이 State aggregation 보다 상태를 더 구분하고, 큰 성능저하 없이 더 정확한 결과를 보여줌
Neural Networks
What is a Neural Network?
- 학습목표
- feed forward neural networks 에 대해 이해하기
- 활성화 함수 (activation function) 에 대해 이해하기
- neural network 가 파라미터화된 함수라는 점을 이해하기
-
Simple neural networks
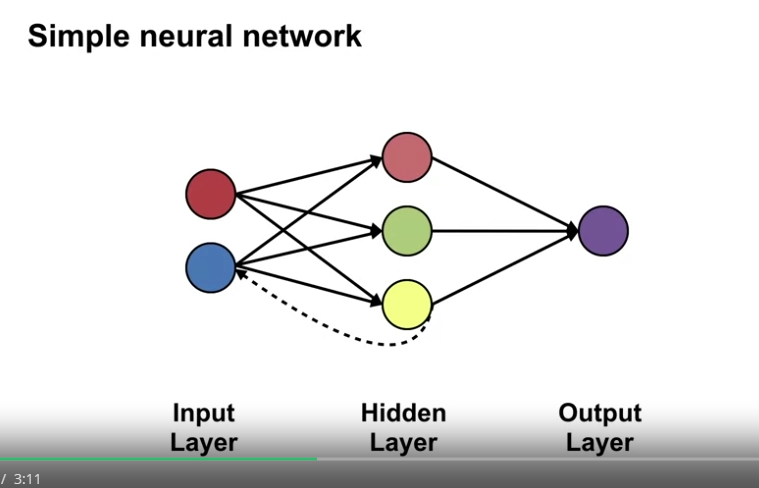
- Neural network 란 입력, 은닉, 출력 층의 구성요소인 노드와 각 층간의 연결을 통해 최종 값을 출력하는 네트워크를 말함
- 각각의 노드와 연결은 일련의 연산과정을 가진다.
- 층과 층의 이동으로 출력 층까지 일방향으로 데이터가 이동하는 network 를 feed forward network 라 한다.
- 가령 출력 값이 다시 층을 거슬러 올라가거나, 본인의 입력값에 영향을 주는 경우 이를 recurrent network 라 한다.
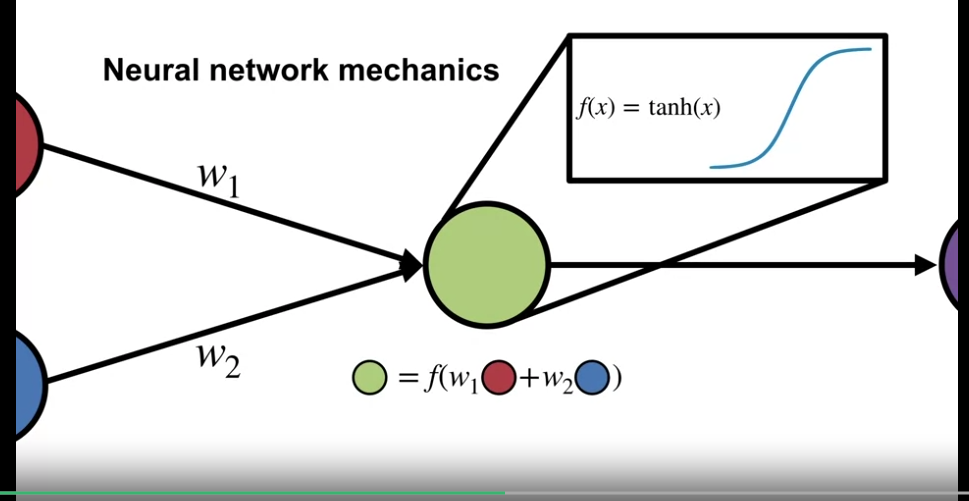
- 노드의 연결은 가중치와 입력값의 곱의 합에 활섬함수를 적용한 형태의 연산을 한다.
- Sigmoid function : s 자 형태의 함수로 tanh 가 여기에 속함
- logistic function : ReLU ($f(x) = x$ if $x>0$ or 0), thresholding units ($f(x) = 1$ if $x>0$ or 0)
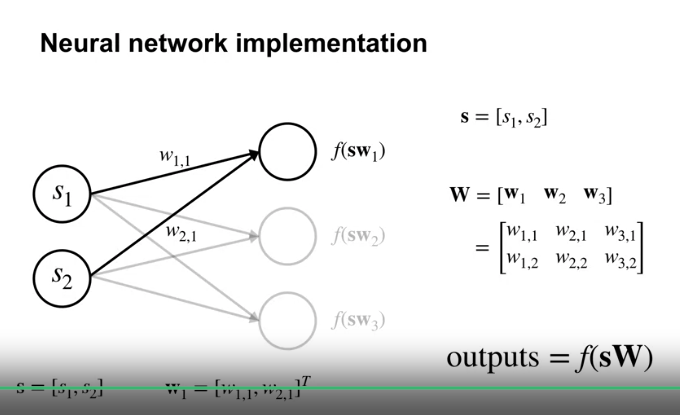
- Neural network 의 연산을 함수로 표현하면 위와 같다.
- 다음 층이 최종 출력층이 아니라면, 위의 값은 다시 입력 층이 된다.
Non-linear Approximation with Neural Networks
- 개요
- Tile coding 은 예측을 위해 고정된 feature 의 집합을 생성하는 하나의 방법이다.
- 신경망은 유용한 feature 의 집합을 학습하기 위한 전략을 제공한다.
- 학습목표
- 신경망이 어떻게 feature 를 생성하는지 이해하기
- 신경망은 상태에 대한 비선형 함수임을 이해하기
-
Non-linear representations
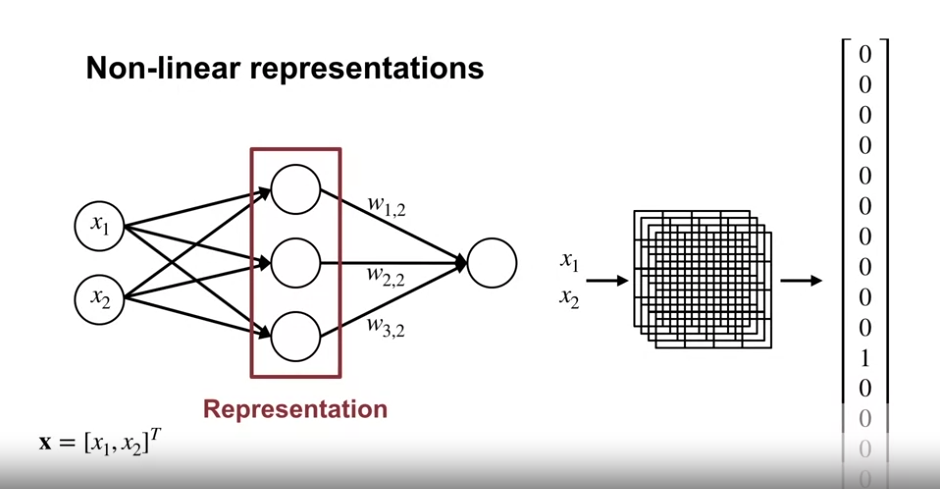
- 신경망을 생성할 때, 초기 가중치 값을 설정하는 작업이 필요하다.
- $\textbf{w}_{\it{init}} \sim \mathscr{N} (\mu, \sigma)$
- 이 작업은 중요한 작업이고 추후에 다룬다.
- 하나의 노드에서는 아래와 같은 연산이 이루어진다.
- $f(w_1 x_1 + w_2 x_2)$
- 노드로 향하는 입력값(노드) : $x_1, x_2$
- 입력값과 노드를 연결하는 가중치(화살표) : $w_1, w_2$
- 위 곱연산의 합계 이후 적용되는 활성화(비선형) 함수 : $f()$
- 위 활성화 함수 적용 이전의 연산은 행렬곱의 연산으로 표현된다.
- 이러한 연산이 적용된 하나의 층은 다음 층의 feature 가 된다.
- 위 프로세스는 Tile coding 의 것과 크게 다르지 않다.
- 상태의 값을 feature 로 재표현 하는 것
- 신경망과 Tile coding 모두 non-linear mapping 을 하게 된다.
- Tile coding 과 신경망의 차이
- Tile coding 의 경우 학습 이전에 타일의 크기, 타일의 형태, 타일링 수 등의 초기 고정 파라미터가 설정 된다.
- 신경망의 경우 층의 수, 노드의 수, 활성화 함수와 같은 초기 고정 파라미터가 있다.
- 하지만 신경망의 경우 학습 중에 바뀌는 파라미터도 있다. (가중치와 편향)

- 위의 이미지는 신경망에서 기학습된 노드의 출력값을 시각화한 것이다.
- 위와 같이, 각 영역(x,y 좌표)이 활성화 정도가 0,1 로만 표현되는 것이 아니고 (정도의 차이), 비선형으로 표현됨을 볼 수 있다.
- 신경망을 생성할 때, 초기 가중치 값을 설정하는 작업이 필요하다.
Deep Neural Networks
- 개요
- 신경망 아키텍쳐의 선택은 성능에 큰 영향을 준다.
- 노드 수, 활성화 함수, 노드 배열, 연결 방식 등
- 신경망의 깊이가 학습에 어떠한 영향을 주는지 알아본다.
- 신경망 아키텍쳐의 선택은 성능에 큰 영향을 준다.
- 학습목표
- 심층신경망이 여러 개의 층(layer) 으로 구성되어있다는 점을 이해하기
- 위의 층의 깊이가 구성과 추상화를 통해 특징을 학습하는 데 도움이 된다는 점을 이해하기
- Modular architecture
- 신경망 아키텍쳐에서 각 층을 모듈로 이해할 수 있다. 이 층은 추가되거나 제거될 수 있다.
- 신경망에서의 깊이란 이 은닉층의 숫자를 가리킨다.
- Universal approximation
- 이론 상으로 신경망은 깊을 필요가 없다.
- 단 하나의 은닉층이 많은 노드를 가짐으로서 (넓이가 넓음) 모든 연속함수를 근사할 수 있다.
- 이를 범용 근사 속성 (Universal approximation property) 이라 한다.
- 하지만 실제경험과 이론에 따르면 깊은 은닉층이 복잡한 함수의 근사를 더 쉽게 해준다는 결과가 있다.
-
Compositional features
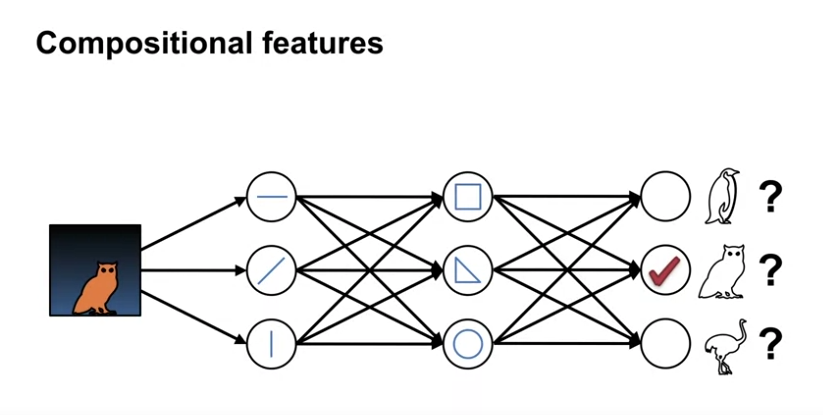
- 신경망의 깊이는 구성상의 특성을 허용한다.
- 모듈식 구성 요소를 결합하여 보다 전문화된 기능을 생성할 수 있다.
- 위 그림과 같이, raw data 에서 바로 올빼미를 추출하는 것보다, raw 한 요소에서 보다 복합적인 요소를 거처 식별하는 것이 더 효율적이다.
- 층을 겹치거나 노드를 추가함으로써, 더 복잡한 함수를 표현해낼 수 있다.
-
Levels of abstraction
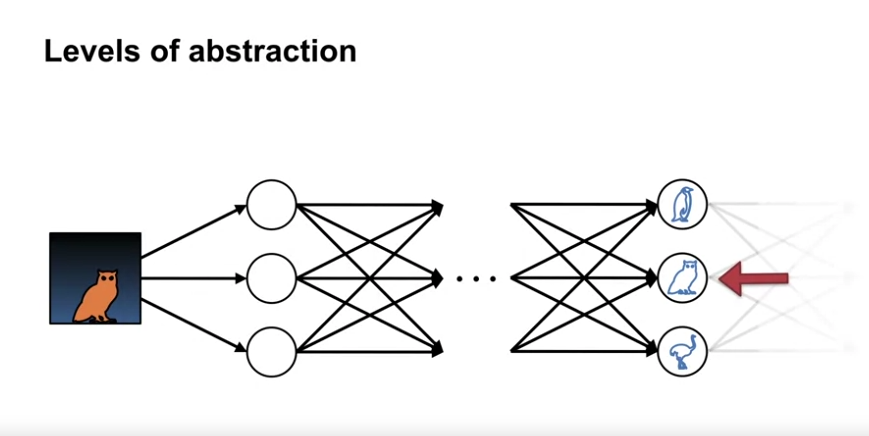
- 신경망의 층은 특징의 추상화에도 도움을 준다.
- 예를 들어 위의 그림이 올뺴미임을 식별함에 있어서, 뒷 배경의 요소는 중요한 요소가 아니다.
- 즉, 불필요한 세부 정보를 제거하도록 네트워크를 명시적으로 설계할 수 있다.
- 예를 들어 병목 계층이 그러한데, 연속적인 레이어에서 이전 레이어보다 노드 수를 줄여 핵심적인 요소만 파악하는 것이다.
Training Neural Networks
Gradient Descent for Training Neural Networks
- 개요
- 알고리즘의 업데이트는 매우 간단하며, 대부분의 경우 경사하강법에 기반을 둔다.
- 신경망의 경우에도 위와 동일하다.
- 역전파 알고리즘은 실제로 복잡하지 않으며, 실제로 그냥 경사하강법이다.
- 그러나 경사가 조금 더 복잡한데 이는 내재함수 떄문이다.
- 학습목표
- 신경망에서의 경사 유도
- 신경망에서 경사하강법을 구현
-
Recap on Gradient Descent
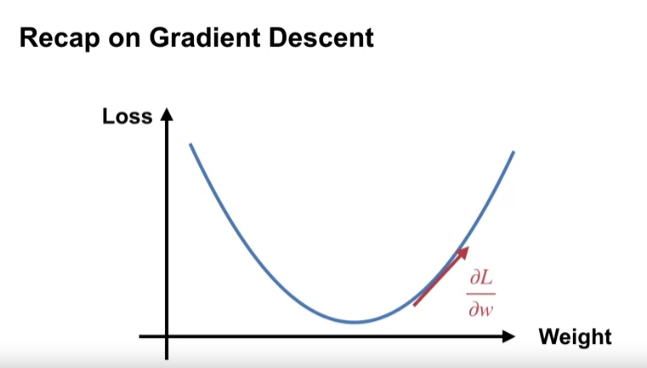
- 선형함수근사에서 첫 단계는 목표와 출력값 간의 차이인 손실을 정의하는 것이다.
- 그 다음 위 손실을 최소화 하는 기울기를 도출한다.
- 즉, 기울기의 반대방향으로 이동하여, 손실을 최소화한다. (변수가 기울기임을 주목)
- 그렇다면 신경망에서 손실함수의 기울기를 어떻게 계산할까?
-
Notation
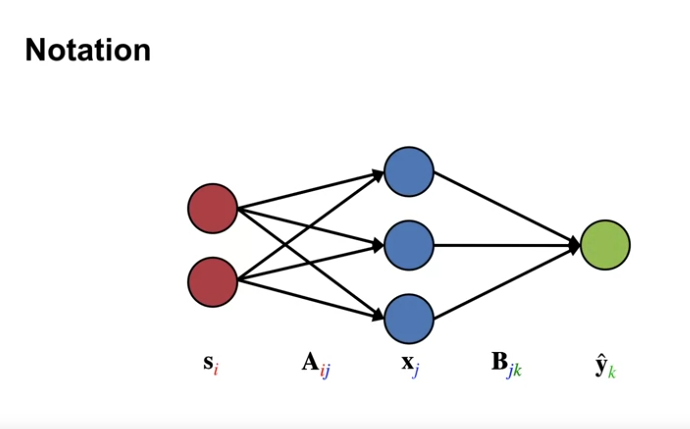
- 네트워크의 입력을 $s$, 출력을 $\hat{y}$ 로 정의한다.
- 은닉층의 학습된 특성(learned features) 을 $x$ 로 정의한다.
- 가중치 $a$ 는 특성을 생성하고, 가중치 $b$ 는 결과값을 생성한다.
- 여기에서 $x$ 와 $\hat{y}$ 와 같은 값들은 벡터로 표현될 수 있다.
- (하지만 엄밀히 말하면 행렬로 표현된다고 보는 것이 맞을 것 같음.)
- (벡터간의 내적 연산은 두 벡터의 유사성을 판단하는 연산이라고 생각할 때…)
- Loss $L$ : $L(hat{y}_k, y_k) = (\hat{y}_k - y_k)^2$
- 위의 손실함수는 이 예에서 쓰이는 예시이다.
-
Goal
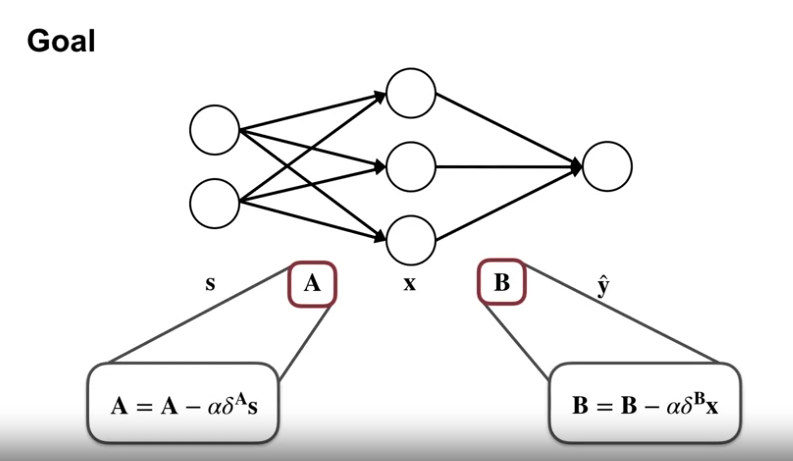
- 위 식은 업데이트 식의 유도 전 원형의 형태이다.
- 업데이트 식과 유사한 부분이 있다.
- $\delta$ : 오류항
- 각각의 입력값과 오류항 관련 값(델타) 를 곱한 값에 대한 업데이트를 진행한다.
- 추후 우리는 델타 A 가 델타 B 를 통해 효율적으로 구해질 수 있다는 것을 볼 것이다.
- 역전파로 A의 에러를 생성하는 것에 도움을 준다.
-
Deriving the gradient

- Chain Rule 을 활용하여 식을 변형한다.
- 최종적으로 위 식에서 델타 B 를 정의하면 식은 단순한 형태로 표현이 될 수 있다.

- 위의 식은 Loss 를 squared error, 활성홤수를 선형함수로 정의했을 때의 예시이다.

- 위 B의 방식과 동일하지만 x 항이 미분하려는 A 항을 포함하고 있다는 점을 반영해야 한다.
-
The backprop algorithm

- 계산량을 줄이기 위해 출력층에서부터 계산해온 값을 활용하는 것이 역전파의 주요 아이디어이다.

- 위는 ReLu 를 활성화함수로 사용하고, 출력에 선형 유닛을 사용한 신경망의 예시이다.
Optimization Strategies for NNs
- 개요
- 심층망 지도학습은 이미지 식별, 음성인식, 자연어 생성 등의 영역에서 현재 쓰이고 있다.
- 이러한 발전의 원인은 학습데이터와 계산량의 증가에 있다.
- 그러나 위의 발전의 이점을 가져가려면, 학습의 개선 또한 필요하다.
- 학습목표
- 신경망에서의 초기화의 중요성 이해
- 신경망 학습을 위한 최적화 기술에 대한 서술
-
학습 시작점의 문제
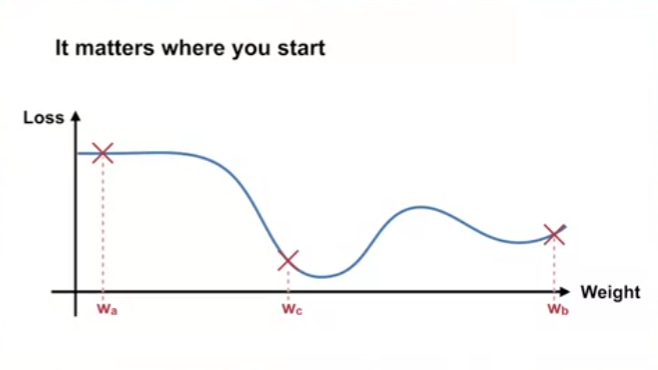
- 학습 시작점은 학습 전반에 매우 큰 영향을 준다.
- 가령 평평한 손실함수 기울기의 지점에서 시작한 경우 학습이 거의 진행되지 않는다.
- 기울기가 있는 지점에서 시작한 경우 지역 최소값을 찾을 수 있다.
- 전역 최저점 근처에서 학습을 시작한 경우 빠르게 최고의 결과를 얻을 수 있다.
-
Weight initialization
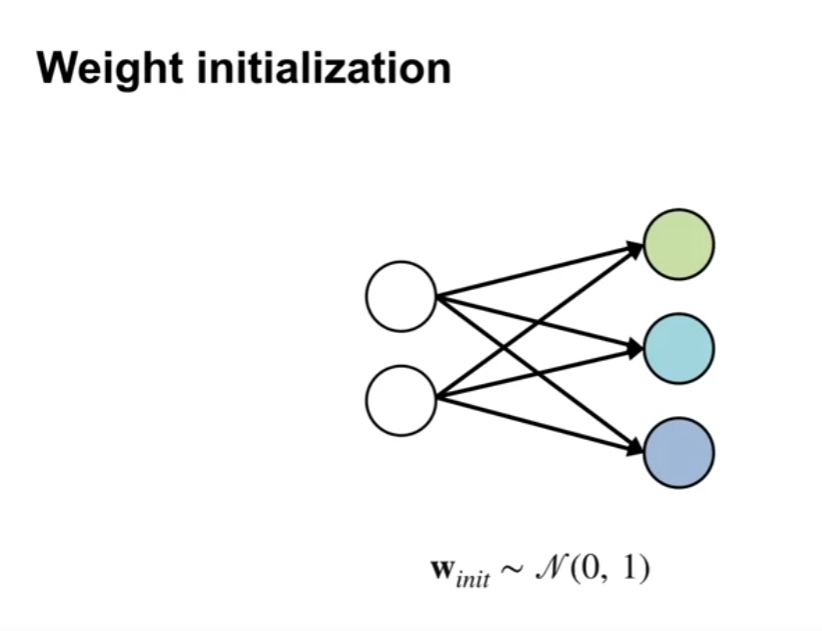
- 가중치를 분산이 작은 정규분포로 초기화하는 기법
- 이것은 잠재적 features 의 집합에 더 많은 다양성을 부여한다.
- 분산이 작다는 전제가 있다면, 각 신경의 출력값이 이웃 신경망과 동일한 범위에 있음을 보장한다.
- 이 전략의 약점은, 입력 뉴런이 추가되면 출력값의 분산이 커진다는 점이다.
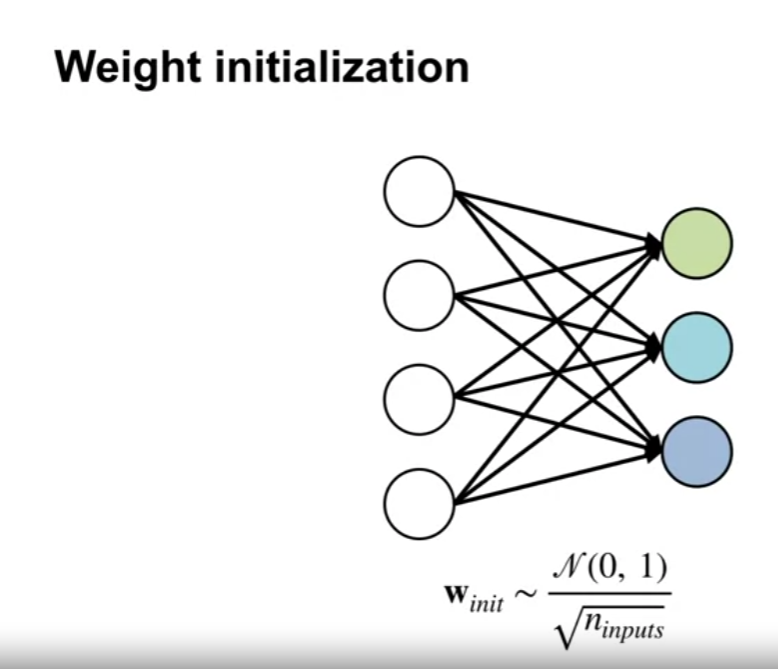
- 우리는 위 단점을 입력값의 수에 대한 제곱군으로 스케일링 하여 극복할 수 있다.
-
Update momentum (heavy-ball method)

- 일반적인 확률적 경사하강 업데이트에 모멘텀 M 항을 더한 것
- 모멘텀은 $\lambda$ 와 함께 점점 감쇠된다.
- 최근 업데이트 방향이 모두 같다면, 모멘텀이 증가한다.
- 최근 업데이트 방향이 서로 상충되면, 모멘텀이 감소한다.
-
Vector step sizes
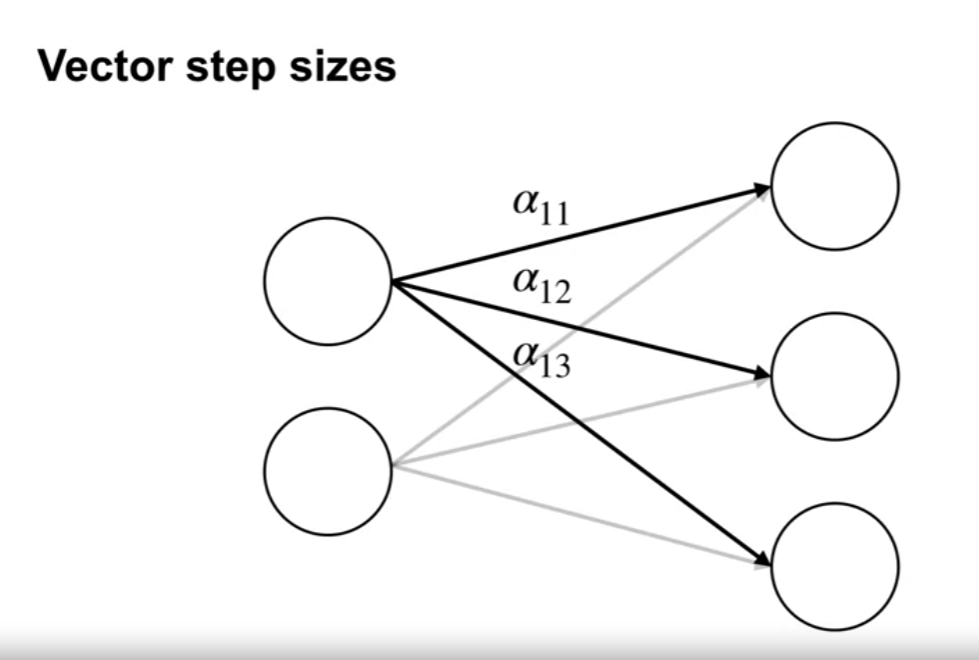
- $W_{t+1} = W_t - \eta \nabla J(W_t)$
- $W_t$ 와 $W_{t+1}$ 은 각각 현재와 업데이트된 가중치를 나타냄
- $\eta$ 는 학습률(learning rate) 벡터이며, 각 매개변수에 대해 다른 값을 가질 수 있음
- $\nabla J(W_t)$ 는 현재의 그래디언트 값 (Loss 함수에 대한 각 매개변수의 편미분)
- 벡터 스텝 사이즈 기법은 네트워크가 복잡하거나 데이터가 불균형한 경우에 유용하며, 경사하강법의 수렴속도를 향상시킬 수 있음
- 그러나 올바른 학습률 벡터를 선택하는 것이 중요하며, 이를 위한 다양한 최적화 기법이 개발되고 연구되고 있음
- $W_{t+1} = W_t - \eta \nabla J(W_t)$
David Silver on Deep Learning + RL = AI?
-
About reinforcement learning
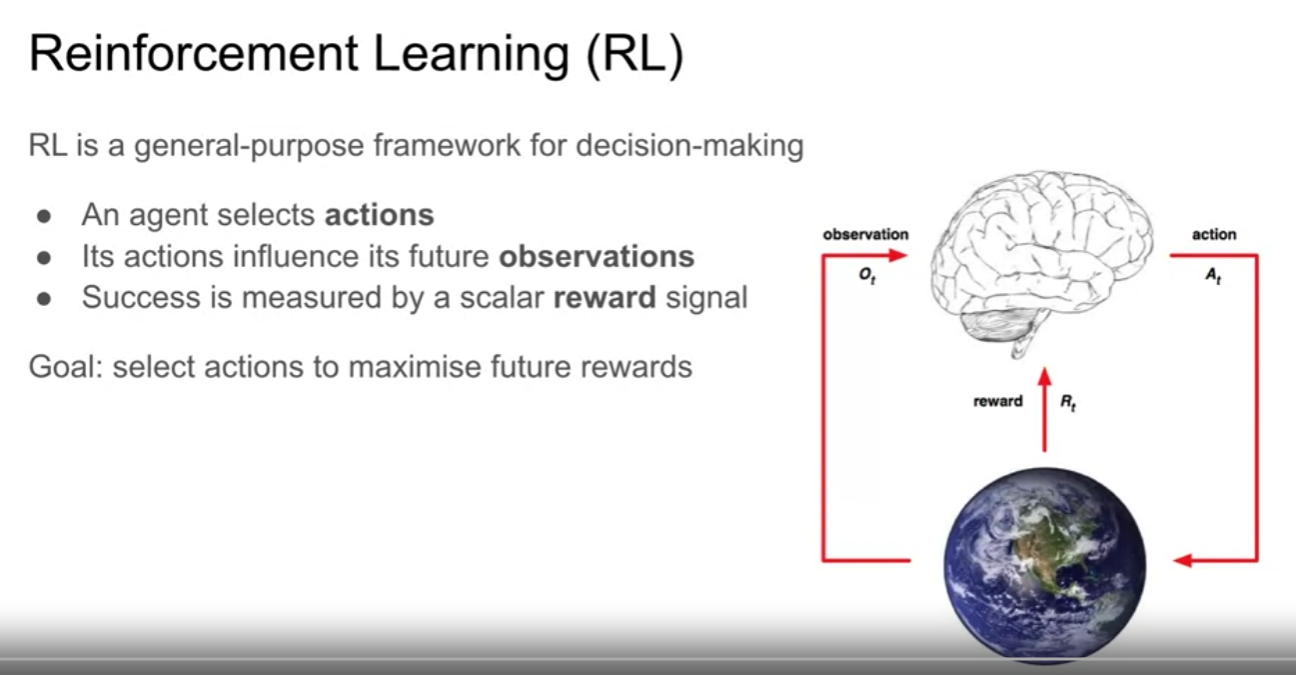
- 강화학습은 모든 종류의 다른 의사결정 문제에 대한 광범위한 목적의 프레임워크이다.
- agent 가 있고, agent 가 world 에서 actions 를 행한다.
- agent 의 action 이 world 에 영향을 주고, 관측 값을 agent 에 준다.
- agent 는 world 에서 performance 를 최대로 할 수 있는 action을 택한다.
- 위 performance 는 reward signal 로 측정된다.
- 강화학습은 표현 학습에 대해 매우 일반적인 방식으로 생각하는 방법이다.
- 강화학습은 모든 종류의 다른 의사결정 문제에 대한 광범위한 목적의 프레임워크이다.
-
About deep learning
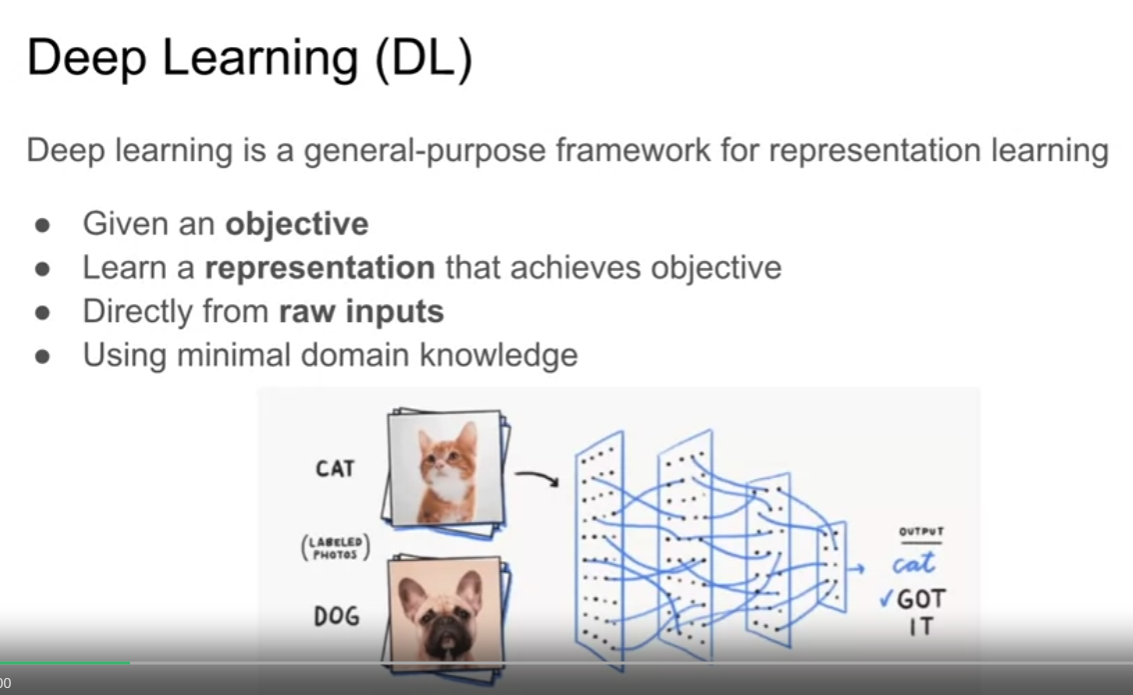
- 우리가 어떤 목적을 가지고 있을 때 deep learning 은 목적을 달성하기 위한 표현을 만드는 방법을 제공한다.
- 입력값을 시스템 내 어떠한 필터를 거쳐 표현을 만드는 방법
- 어떠한 종류의 특성을 생성하여, 입력 값으로 문제를 해결하는데 도움을 주는 방법
- 최소한의 도메인 지식을 활용
- 우리가 어떤 목적을 가지고 있을 때 deep learning 은 목적을 달성하기 위한 표현을 만드는 방법을 제공한다.
-
About deep reinforcement learning 1

- 위의 reinforcement learning 과 deep learning 을 합친 형태
- 문제와 목표는 reinforcement learning 으로 정의될 수 있다.
- deep learning 은 메커니즘을 제공한다.
- About deep neural network
- multi-layered function
- a compositional function
- a function of a function of a function
- 예시
- 어떠한 입력값이 시스템에 들어온다. (예를 들어 강아지나 고양이 이미지)
- 한 묶음의 다양한 함수를 통과한다. (이 함수는 내부 상태나 특징을 제공하게 된다.)
- 위의 내부상태, 특징들은 가중치 $w$ 와 작용하게 된다.
- 위의 다양한 층의 계산을 거쳐, 어떠한 형태의 출력물을 제공한다. (예를 들어 이것이 강아지인지 고양이인지)
- 결과적으로 위의 것으로 목적을 정의하게 되는데, 이것을 loss 라 칭한다.
- loss 는 시스템이 얼마나 잘했는지를 알려준다.
- 계산을 정방향이 아닌 역방향으로 하는 점
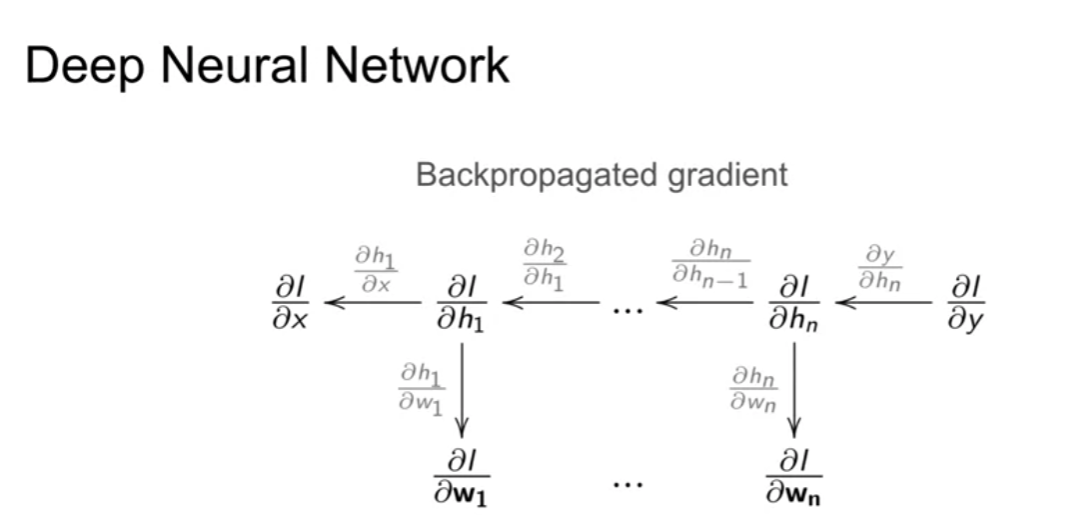
- Chain rule 을 이용한 역전파
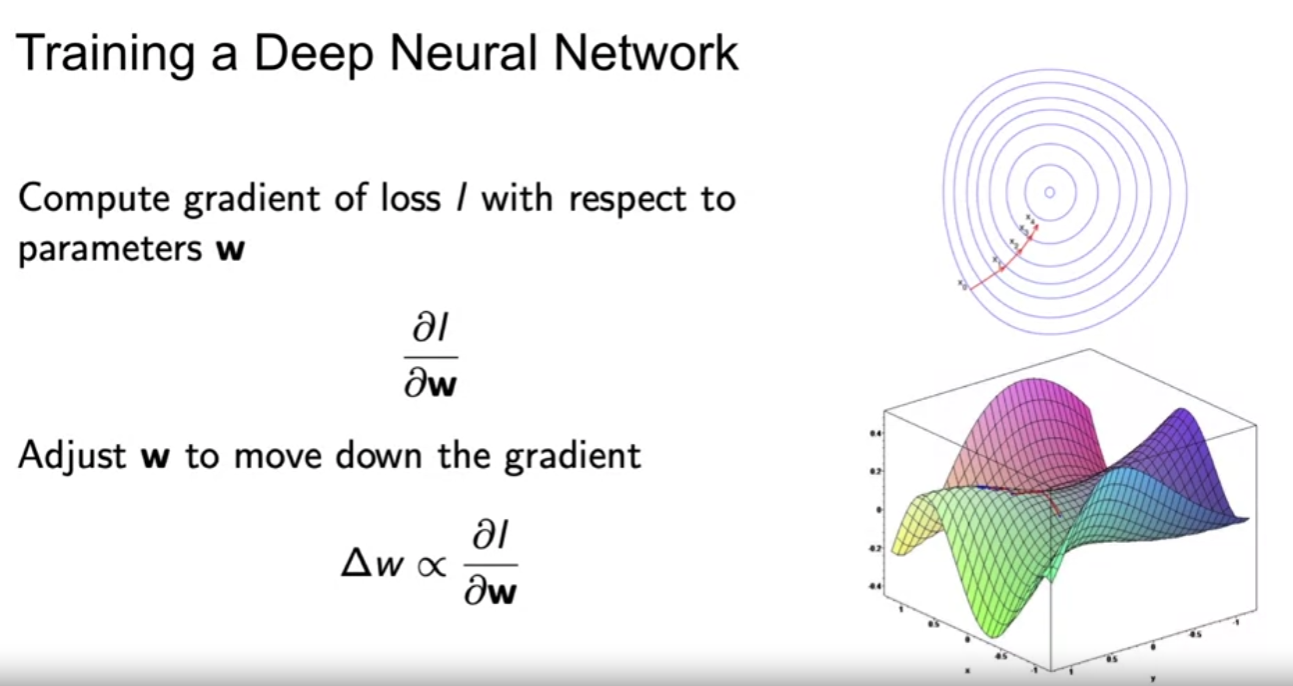
- 결국 심층신경망의 훈련은 loss 함수의 관련 파라미터에 대한 기울기를 토대로, 파라미터의 값을 조율해 에러 값을 줄이는 것이 목표이다.
- Anatomy of an RL Agent
- RL 에서 에이전트의 구성 요소에 무엇이 포함되어 있는지는 중요한 문제이다.
- 이는 무엇을 학습하고자 하는 것인가에 대한 문제이다.

- 에이전트에 정책이 포함되어 있는 경우 : 에이전트의 행동을 결정 (a policy-based approach to RL) - 정책이 확률론적임
- 에이전트에 가치함수가 포함되어 있는 경우 : 에이전트의 보상에 대한 예측을 함 (a value-based RL agent) - 각 상태/행동의 가치를 고려하여 최적의 행동을 수행함
- 에이전트에 모델이 포함되어 있는 경우 : 에이전트가 환경이 어떻게 작용할지를 예측 (a model-based approach to RL) - 다음 상태 및 보상을 예측하여 다음 동작을 계획함
- RL 에서 에이전트의 구성 요소에 무엇이 포함되어 있는지는 중요한 문제이다.
- About deep reinforcement learning
- 심층 신경망은 근사함수로서 사용
- Policy, Value function, Model 중 어느 하나에 대한 표현을 한다.
- 위에 대한 loss function 을 고려한다. (아래는 예시이다.)
- Policy-based RL : Policy Gradient
- Value-based RL : TD error
- Model-based RL : Next-step prediction error
- 심층 신경망은 근사함수로서 사용
- 학습목표
- 단일 은닉층 신경망의 기울기 계산
- 임의의 심층 네트워크에 대한 기울기를 계산하는 방법 이해
- 신경망 초기화의 중요성 이해
- 신경망 초기화 전략 설명
- 신경망 훈련을 위한 최적화 기술 설명
강의 개요 (과정 로드맵)
- 가치함수를 테이블로 표현할 수 있는 경우
- 가치함수를 테이블로 표현할 수 없는 경우
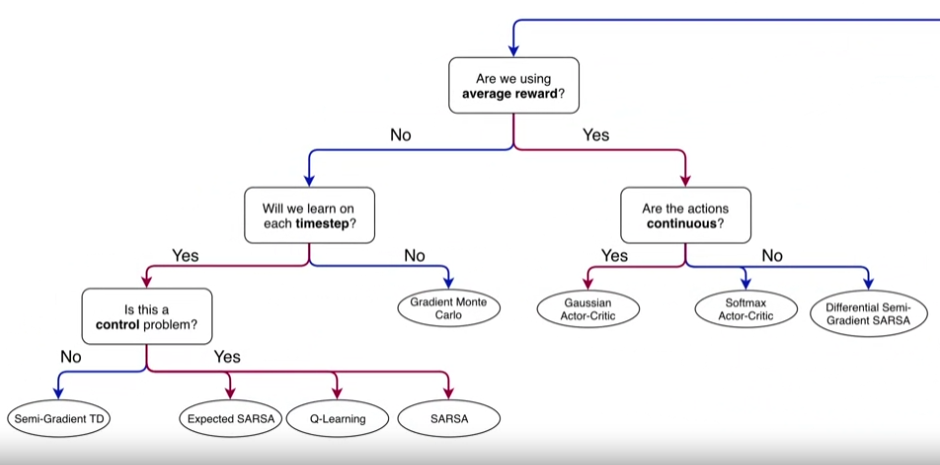
관련 자료 (RLbook Pages 197-209)
- On-policy Prediction with Approximation (개요)
- 이 장에서는 강화학습의 함수 근사의 학습을 다룬다.
- 함수 근사는 On-policy 데이터의 상태가치함수를 추정하기 위해 사용
- 즉, 알고있는 정책 $\pi$ 로 생성한 경험으로 $v_\pi$ 를 근사하고자 한다.
- 여기에서 눈여겨볼 점은 가치 함수 근사는 테이블로 나타내지 않고, 파라미터화된 함수의 형태 (벡터 $\textbf{w}$ $\in \mathbb{R}^d$) 를 사용한다는 점이다.
- $\hat{v}(s,$ $\textbf{w}) \approx v_\pi(s)$
- 상태 $s$ 와 주어진 가중치 벡터 $\textbf{w}$ 의 근사된 값을 나타냄
- $\hat{v}$ 는 상태의 요소에 대한 선형함수일 수 있고, $\textbf{w}$ 는 요소에 대한 가중치 벡터일 수 있음.
- 더 일반적으로 $\hat{v}$ 는 다중 인공 신경망 (multi-layer artificial neural network) 에 의해 계산되는 함수일 수 있고, $\textbf{w}$ 는 모든 층에 연결된 가중치일 수 있음.
- 혹은 $\hat{v}$ 는 의사결정나무 (decision tree) 에 의해 계산되는 함수일수 있고, $\textbf{w}$ 는 모든 분기점과 트리의 리프 값을 정의하는 모든 숫자일 수 있음.
- 일반적으로 가중치의 수 ($\textbf{w}$ 의 차원 수) 는 상태의 수보다 훨씬 작고 ($d \ll | \mathcal{S} |$), 하나의 가중치의 변화는 다수의 상태의 예측값을 바꾸게 된다.
- 따라서 하나의 상태가 업데이트되면 일반화되어, 다른 다수의 상태의 값에 영향을 주게 된다.
- 이러한 일반화 (generalization) 는 학습을 더욱 강력하게 하는 동시에 이해와 관리를 어렵게 한다.
- 놀랍게도 강화학습을 함수 근사로 확장하면 전체 상태를 사용할 수 없는 부분적으로 관찰이 가능한 문제에도 적용할 수 있다.
- $\hat{v}$ 에 대한 파라미터화된 함수 형식이 추정값이 상태의 특정 요소에 의존하는 것을 허용하지 않으면, 이는 해당 측면을 관찰할 수 없는 것과 같다.
- 실제로 이 책의 이 부분에 제시된 함수 근사를 사용하는 이론적 결과물은 부분적 관찰의 케이스에도 잘 적용된다.
- 그러나 함수 근사가 할 수 없는 것은 과거 관찰에 대한 기억으로 상태의 표현을 강화하는 것이다.
- 이러한 부분의 일부는 섹션 17.3 에서 간략하게 논의하기로 한다.
- 이 장에서는 강화학습의 함수 근사의 학습을 다룬다.
- Value-function Approximation
- 이 책의 모든 예측 방법 (prediction methods) 은 특정 상태의 값을 backed-up value 혹은 update target 으로 이동시키는, 추정 가치 함수 (estimated value function) 의 업데이트이다.
- 개개의 업데이트를 표기법 $s \mapsto u$ 로 나타내도록 한다.
- $s$ 는 상태 업데이트를 뜻하고, $u$ 는 $s$ 의 추정값이 향하는 update target 을 뜻한다.
- Monte Carlo update : $S_t \mapsto G_t$
- TD update : $S_t \mapsto R_{t+1} + \gamma \hat{v} (S_{t+1},$ ${\textbf{w}}_t)$
- n-step TD update : $S_t \mapsto G_{t:t+n}$
- DP policy-evaluation update : $s \mapsto$ $E_{\pi}$ $[ R_{t+1} + \gamma \hat{v} (S_{t+1},$ ${\textbf{w}}_t)$ $| S_t = s ]$
- $s$ 는 임의의 상태를 뜻하며, $S_t$ 는 실제 경험에서 마주하게 된 상태를 의미한다.
- 지금까지의 실제 업데이트는 $s$ 의 추정 값에 대한 테이블 항목이 $u$ 방향으로 약간 이동되며, 다른 모든 상태의 추정값은 변경되지 않은 채로 남아 있었음.
- 이제는 업데이트를 구현하기 위해 임의로 복잡하고 정교한 방법을 허용, $s$ 에서의 업데이트는 다른 많은 상태의 추정 값도 변경되도록 일반화한다.
- 이러한 방식으로 입력-출력 예제를 모방하는 방법을 학습하는 기계 학습 방법을 지도 학습 방법 (Supervised learning) 이라고 한다.
- 출력이 $u$ 와 같은 숫자인 경우 이 프로세스를 종종 함수 근사라고 한다.
- 우리는 각 업데이트의 $s \mapsto g$ 를 훈련 예제로 전달하여 값의 예측을 위해 이러한 방법을 사용한다.
- 그런 다음 그들이 생성하는 근사 함수를 가치 추정 함수로 본다.
- 이러한 방식으로 각 업데이트를 전통적인 학습 예제로 보면, 가치 예측을 위한 광범위한 함수 근사 방법을 사용할 수 있다.
- 원칙적으로, 인공신경망, 의사결정트리, 다양한 종류의 다변량 회귀 등 다양한 지도학습의 학습 방법을 모두 사용 가능
- 그러나 모든 함수 근사 방법이 강화 학습에 사용하기 적합한 것은 아님.
- 정교한 인공신경망과 통계 방법은 다중 패스가 이루어지는 정적 훈련 세트를 가정한다.
- 그러나 강화학습에서는 에이전트가 환경 혹은 환경 모델과 상호작용하는 동안 학습이 온라인으로 이루어질수 있다는 것이 중요
- 이를 위해 점진적으로 획득된 데이터로부터 효율적으로 학습할 수 있는 방법이 필요함.
- 또한 강화학습에서는 일반적으로 비정상성 (nonstationary target) (시간에 따라 변하는 목표) 를 처리할 수 있는 함수 근사 방법이 필요함.
- 예를 들어 GPI (generalized policy iteration) 기반 방법에서는 $\pi$ 가 변경되는 동안 $q_\pi$ 를 학습하려고 하는 경우가 많음.
- 정책이 동일하게 유지되더라도 훈련 예제의 목표 값이 부트스트래핑 방법 (DP, TD 등) 으로 생성된 경우 비정상성임.
- 이러한 비정상성을 쉽게 처리할 수 없는 방법은 강화학습에 적합하지 않다.
- The Prediction Objective ($\overline{VE}$)
- 예측을 위한 명시적인 목표
- Tabular case 의 경우
- 예측을 위한 명시적인 목표를 지정하지 않았음.
- 학습된 가치함수가 실 가치함수와 정확하게 동일해질 수 있기 때문에 예측 품질에 대한 지속적인 측정이 필요하지 않음.
- 각 상태에서 학습된 값들은 서로 분리되어있었음 (한 상태의 업데이트가 다른 상태에 영향을 주지 않음)
- Function Approximation 의 경우
- 근사를 사용하면 한 상태의 업데이트가 다른 많은 상태에 영향을 미치므로 모든 상태의 값을 정확하게 얻는 것은 불가능
- 가중치보다 훨씬 더 많은 상태가 있으므로, 한 상태의 추정치를 정확하게 만드는 것은 다른 상태의 추정치를 덜 정확하게 만드는 것을 의미
- 이는 어떤 상태에 집중할 지를 정해야 함을 의미
- Tabular case 의 경우
- Mean Squared Value Error, $\overline{VE}$
- 즉, $\mu (s)$ 를 정의해야 함.
- 상태의 분포 $\mu (s) \geq 0, \sum_s \mu(s) = 1$
- 각 상태 $s$ 의 오차에 대해 얼마나 신경 써야할지를 의미
- 상태 $s$ 에서의 오차는 근사값 $\hat{v} (s,$ $\textbf{w})$ 와 참 값 $v_\pi(s)$ 의 차의 제곱을 의미한다.
- 이를 각 상태별 $\mu$ 를 이용해 가중치를 부여하면 아래의 식이 도출됨.
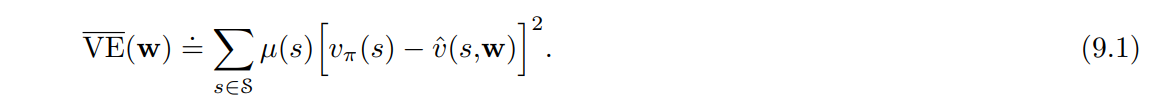
- $\overline{VE}($$\textbf{w}) \doteq \sum_{s \in S} \mu(s)$ $[ v_\pi(s) - \hat{v} (s,$ $\textbf{w}) ]^2$
- 이 측정값의 제곱근, root $\overline{VE}$ 는 근사값과 실제 값이 얼마나 다른지에 대한 대략적 측정값을 제공하며 도표에서 자주 사용됨.
- 위 식에 이미 상태의 분포 값이 들어가 있기에, MSE 값과 연관이 있다고 할 수 있음.
- 즉, $\mu (s)$ 를 정의해야 함.
- $\mu (s)$ 에 대해
- 종종 $\mu (s)$ 는 상태 $s$ 에서 보낸 시간의 비율값이 선택됨.
- on-policy 학습에서 이는 on-policy distribution(분포) 라고 하며, 이 장에서는 이 케이스에 초점을 맞춤
- Continuing tasks 에서 on-policy distribution 은 $\pi$ 아래에서 정상성 분포이다.
- 정상성 분포를 가진다고 가정하는 것.
- 에피소드에서 무한한 상태를 수집할 수는 없으니, 일정 정도를 수집하여 분포를 구하고 이 분포가 정상 분포인 것을 가정하는 것이다.
-
The on-policy distribution in episodic tasks

- 에피소드 작업에서 on-policy distribution 은 에피소드의 초기 상태가 선택되는 방식에 따라 약간 다르다.
- $\eta(s) = h(s) + \sum_{\bar{s}} \eta(\bar{s}) \sum_a \pi (a | \bar{s} ) p(s | \bar{s},a)$, for all $s \in S$. (9.2)
- $h(s)$ : 각 상태 s 가 첫 에피소드 시작일 확률
- $\eta(s)$ : 에피소드에서 상태 $s$ 에 머무는 비율 (s에 방문하는 time step 수)
- 에피소드가 $s$ 에서 시작하거나 이전 상태 $\bar{s}$ 에서 $s$ 로 전이가 일어난 경우
- 위 식은 이전 상태의 time-step 비율을 이용해 현 상태의 비율을 구하는 식이다.
- $\eta(s)$ 를 정규화 (on-policy distribution)
- $\mu(s) = \frac{\eta(s)}{\sum_{s’} \eta(s’)}$, for all $s \in S$. (9.3)
- $s’$ : 상태 $s$ 를 포함한 다른 모든 상태를 의미
- 이것은 할인이 없는 경우에 대한 것임.
- 할인이 있는 경우 9.2의 식의 두번째 항에 $\gamma$ 를 적용해야 함.
- 여기에서 할인의 역할은 에피소드의 확률적인 시작과 종료를 다루기위한 요소로 사용되는 것임.
- $\mu(s) = \frac{\eta(s)}{\sum_{s’} \eta(s’)}$, for all $s \in S$. (9.3)
- 연속적인 케이스와 에피소드 케이스 두 가지의 경우 비슷하게 동작하나, 근사하는 경우 완전히 분리해서 생각해야 한다. (향후 언급)
- 위의 $\overline{VE}$ 로 학습목표 지정이 완료
- 그러나 $\overline{VE}$ 가 강화학습에 적합한 성능의 목표인지 명확하지 않음.
- 가치함수를 학습하는 궁극적인 이유는 더 나은 정책을 찾는 것임.
- 이 목적을 위한 최고의 가치함수가 반드시 $\overline{VE}$ 를 최소화하는데 최적인 것은 아님.
- 지금은 $\overline{VE}$ 에 중점을 둔다.
- $\overline{VE}$ 학습목표의 이상적인 목표와 현실적 목표
- 이상적인 목표 : 가능한 모든 $\textbf{w}$ 에 대해 $\overline{VE}(w^{*}) \leq \overline{VE}(w)$ 인 전역 최적의 가중치 벡터 $\textbf{w*}$ 를 찾는 것
- 위 목표를 찾는 것은 선형과 같은 간단한 함수 근사에서는 가능하나, 인공신경망이나 의사결정트리와 같은 복잡한 함수근사에서는 거의 불가능하다.
- 복잡한 함수근사에서는 이에 미치지 못하는, 지역 최적, $\textbf{w*}$ 와 유사한 수렴값을 찾게 된다.
- 즉, 모든 상태에 대해 오차를 구해 합한 값 $\overline{VE}$ 의 변수 $\textbf{w}$ 에 대해, 전역최소값을 가지는 $\textbf{w}$ 는 구하기 힘들다는 이야기이다.
- 이러한 수렴의 보장은 약간만 안심할 수 있지만, 일반적으로 비선형 함수 근사의 가능한 최선으로 여겨지고, 대부분의 경우 이정도로 충분하다.
- 강화학습의 관심있는 많은 케이스의 경우 최적에 대한 수렴을 보장하지 않고, 또한 최적치에 대한 지정된 범위 내의 수렴 또한 보장하지 않는다.
- 어떠한 방법의 경우 $\overline{VE}$ 로의 무한한 접근이 한계치를 넘어 발산하기도 한다.
- 마지막 두 섹션은 광범위한 가치 추정을 위한 강화학습 방법에 광범위한 함수 근사 방법을 결합하는 프레임워크이다.
- 전자의 업데이트를 사용하여 후자에 대한 훈련 예제를 생성한다.
- 또한 $\overline{VE}$ 성능 측정을 통한 최소화의 촉진에 대해서 살펴본다.
- 가능한 함수 근사 방식의 범위는 모두 다루기에 광범위하며, 대부분의 경우 신뢰할 수 있는 평가나 권장사항을 만들기에 알려진 정보가 너무 적다.
- 우리는 몇 가지 가능성에 대해서만 살펴본다.
- 이 챕터의 나머지 부분에서 경사 원리를 기본으로 한 함수 근사 방법에 집중하며, 이 중에서도 선형 경사 하강법에 중점을 둔다.
- 우리는 이러한 방법이 특히 유망하다고 생각하며, 핵심적인 이론적 문제를 드러낸다고 생각한다. (또한 단순하기도 하다.)
- 예측을 위한 명시적인 목표
- Stochastic-gradient and Semi-gradient Methods
- Stochastic Gradient Descent (SGD) : 확률적 경사하강법
- 모든 함수 근사화 방법 중 가장 널리 사용되는 방법으로 온라인 강화 학습에 특히 적합함
- 확률적이라는 뜻은, 모든 표본을 구해 경사하강법을 진행하는 것이 아닌, 일부 표본 데이터(상태)에 대해서만 적용한다는 의미임.
- 경사 하강법에서 가중치 벡터는 고정된 실수 값을 구성요소로 가진 열 벡터이다.
- $\textbf{w} \doteq (w_1, w_2, …, w_d)^\top$
- 여기서 $\top$ 는 전치행렬을 의미한다. 수평의 row 벡터를 수직의 column 벡터로 전환하는 것을 의미
- $\textbf{w} \doteq (w_1, w_2, …, w_d)^\top$
- 근사가치함수 $\hat{v} (s, \textbf{w} )$ 는 모든 $s \in S$ 에 대한 $\textbf{w}$ 의 미분 가능한 함수이다.
- 우리는 $\textbf{w}$ 를 매 이산 time-step 의 시리즈 $t = 0,1,2,3,…$ 각각에 업데이트를 할 것이므로, $\textbf{w}_t$ 라는 표기법이 필요하다.
- 지금부터 우리는 각 스텝에서 새 예시 $S_t \mapsto v_\pi (S_t)$ (아마도 무작위로 선택된 $S_t$ 와 정책 하의 참 값) 를 관측한다고 가정한다.
- 위의 상태 값은 환경과의 상호작용을 통한 연속적인 상태가 되겠지만, 여기에서는 그렇게 가정하지 않는다.
- 비록 각 상태 $S_t$ 에 정확하게 옳은 참 값 $v_\pi (S_t)$ 이 제공된다 해도 여전히 어려운 문제가 있다.
- 우리의 함수 근사기는 한정된 자원과 그로 인한 한정된 해결책을 가지고 있다.
- 특히 일반적으로 모든 상태를 가지거나, 정확히 옳은 샘플들을 가지는 $\textbf{w}$ 는 존재하지 않는다.
- 추가적으로 우리는 예제에 보여지지 않은 다른 모든 상태에 대해서도 일반화를 해야 한다.
- 우리는 (9.1) 에 주어진 $\overline{VE}$ 를 최소화 하는동안 각각의 상태가 동일 분포 $\mu$ 로 나타난다고 가정한다.
- 이러한 케이스에서 좋은 전략은 관측된 예제에서 에러값을 최소화하는 것을 시도해보는 것이다.
-
확률적 경사 하강법 (SGD, Stochastic Gradient Descent) 은 각 예제 후에 해당 예제에서의 에러를 가장 많이 줄이는 방향으로 가중치 벡터를 소량 조정함으로서 위 방법을 수행한다.
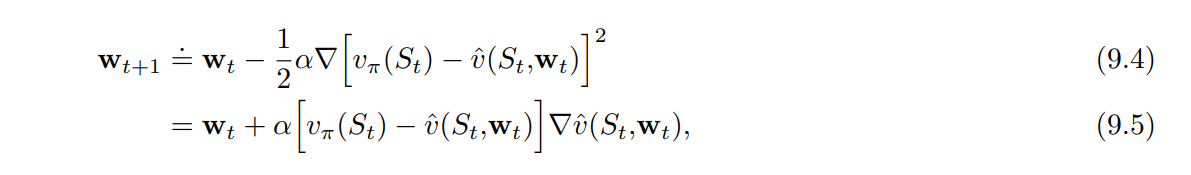
- $\alpha$ : 양수의 step-size 파라미터
- $w_{t+1} \doteq w_t - \frac{1}{2} \alpha \nabla [ v_\pi(S_t) - \hat{v}(S_t, w_t) ]^2$
- $v_\pi (S_t)$ : 상태 $S_t$ 에서의 실 가치값
- $\hat{v} (S_t, w_t)$ : 함수 근사를 통해 예측된 가치
- 손실함수 $\textbf{L}$
- $\frac{1}{2} [ v_\pi(S_t) - \hat{v}(S_t, w_t) ]^2$
- 분산 : 편차의 제곱 평균
- 즉, 위 식은 가중치 벡터를 학습률을 반영한 손실함수의 경사만큼 뺀 값
- 손실함수의 값을 최소화 하는 방향으로 이동 (기울기의 반대방향)
- 즉, 위 식에서 구하고자 하는 값은 $w_t -\alpha \nabla \textbf{L}$ 이 된다.
- $= w_t + \alpha [ v_\pi (S_t) - \hat{v} (S_t, w_t) ] \nabla \hat{v} (S_t, w_t)$
- 위 식 중 $\nabla \textbf{L}$ 을 구한다는 것의 의미는 손실함수에 대한 $w_t$ 의 기울기 함수를 구한다는 의미 (편미분)
- $\textbf{L}$ 은 $v_\pi (S_t)$ 와 $\hat{v}(S_t,w_t)$ 의 함수이고, 후자는 $w_t$ 에 의존한다.
- $\frac{\partial L}{\partial w_t} = \frac{\partial L}{\partial \hat{v}(S_t,w_t)} \cdot \frac{\partial \hat{v}(S_t,w_t)}{\partial w_t}$
- 각 항에 대한 미분
- $\frac{\partial L}{\partial \hat{v}(S_t,w_t)} = 2 \cdot \frac{1}{2} [ v_\pi (S_t) - \hat{v}(S_t,w_t) ] \cdot (-1) = \hat{v}(S_t,w_t)-v_\pi (S_t)$
- $\frac{\partial \hat{v}(S_t,w_t)}{\partial w_t}$
- 즉, $[ \hat{v} (S_t, w_t) - v_\pi (S_t) ] \nabla \hat{v} (S_t, w_t)$ 이 된다.
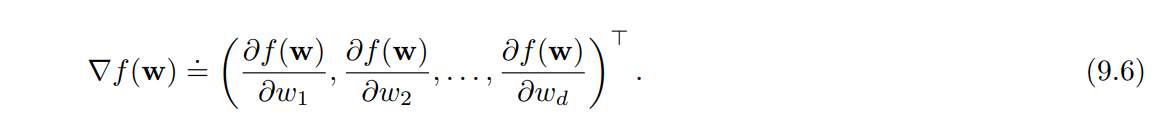
- $f( \textbf{w} )$ : 벡터 w 의 함수.
- $\nabla f( \textbf{w} )$ : 벡터의 구성요소에 대한 편미분
- 위 식은 벡터 $\textbf{w}$ 에 대한 함수 $f( \textbf{w} )$ 를 미분하려면 벡터의 구성요소들로 편미분 해야 함을 나타낸다.
- 이 파생 벡터는 $\textbf{w}$ 에 대한 $f$ 의 경사이다.
- SGD 방식은 경사 하강 (gradient descent) 방식이라 하는데, $w_t$ 의 전반적인 단계가 예시의 제곱 에러 (9.4) 의 음의 기울기 값에 비례하기 때문
- 이는 오차가 가장 빠르게 감소하는 방향이다.
- 확률적으로 선택되었을 수 있는 단일 예에서 업데이트가 완료되면 경사 하강법을 확률적이라고 한다.
- 많은 예를 통해 작은 단계만큼 수행하다 보면, 전반적인 효과는 $\overline{VE}$ 와 같은 평균 측정값을 최소화할 수 있다.
- 한번에 큰 단계로 움직이거나 경사 방향으로 완전히 이동해 해당 예시에서의 에러를 완전히 없앨 수는 없다.
- 모든 상태에 대해 에러가 없을 수 없고, 각각의 다른 상태에서 오직 에러의 균형을 근사화할 수밖에 없기 때문.
- $\alpha$ 의 값이 충분히 작다면, SGD 방식은 지역 최적값으로 수렴하는 것을 보장한다.
-
Stochastic Gradient Descent (SGD) 의 Bootstrapping 개념에 대해
- t 번째 학습 예제의 목표값을 $U_t \in \mathbb{R}$ 로 정의하면, $S_t \mapsto U_t$ 가 되며, 이때 $v_\pi (S_t)$ 의 참 값은 될 수 없지만, 임의의 근사치일 수는 있다.
- 예를 들어 $U_t$ 는 $v_\pi (S_t)$ 의 노이즈 버전일 수 있고, 혹은 $\hat{v}$ 의 부트스트래핑된 목표일 수 있다.
- 우리는 이 경우 (9.5) 의 정확한 업데이트를 수행할 수 없으나, $v_\pi (S_t)$ 를 $U_t$ 로 대체함으로써 근사 업데이트를 진행할 수 있다.
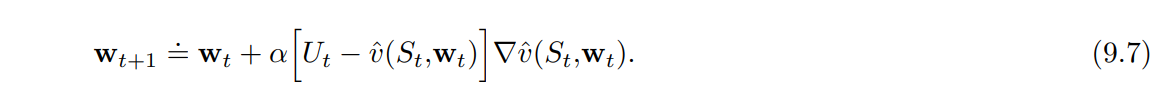
- 만약 $U_t$ 가 편향되지 않은 추정값이라면, 만약 각각의 $t$ 에 $\mathbb{E} [U_t | S_t=s ] = v_\pi (S_t)$ 라면 $w_t$ 는 지역 최적에 수렴함을 보장한다. ($\alpha$ 가 충분히 작을 경우)
- 예를 들어 예시의 상태가 정책 $\pi$ 하에 환경과 상호작용 (혹은 시뮬레이션) 된 것이라면, 상태의 참 값의 정의는 리턴 값의 추측 값이기에, 몬테카를로 목표 $U_t \doteq G_t$ 는 편향이 없는 $v_\pi (S_t)$ 의 추정치이다.
- 따라서 몬테카를로 상태값 예측의 경사하강법 버전은 국소적으로 최적의 솔루션을 찾는 것이 보장된다.
-
gradient monte carlo algorithm 의 psuedo code

- $\hat{v} : S \times \mathbb{R}^d \to \mathbb{R}$
- $S$ : 상태 공간을 의미
- $\mathbb{R}^d$ : 실수의 $d$ 차원 벡터 공간을 의미
- $\mathbb{R}$ : 실수를 의미
- 따라서 $\hat{v}$ 함수는 상태 $s \in S$ 와 실수 벡터 $w \in \mathbb{R}^d$ 의 입력을 받아 실수를 출력한다는 의미이다.
- $\hat{v} : S \times \mathbb{R}^d \to \mathbb{R}$
- Semi-gradient (bootstrapping) methods
- $v_\pi (S_t)$ 의 부트스트래핑 추정 (9.7) 에서 목표가 $U_t$ 로 사용되는 경우 동일한 보장을 얻지 못한다.
- 부트스트래핑 목표 n-step 반환값 $G_{t:t+n}$ 또는 DP 목표 $\sum_{a,s’,r} \pi (a|S_t) p(s’,r | S_t,a) [ r+\gamma \hat{v} (s’,w_t) ]$ 모두 가중치 벡터 $w_t$ 의 현재 값에 따라 달라짐. 이는 해당 대상이 편향될 것이며 실제 경사하강법을 생성하지 않음을 의미
- 이는 (9.4), (9.5) 의 식에서 주요 단계가 $w_t$ 와 독립적인 대상에 의존하는 것에서 알 수 있음.
- 따라서 $v_\pi (S_t)$ 대신 부트스트래핑 추정이 사용된 경우 이 단계는 유효하지 않게 됨.
- 가중치 벡터 $w_t$ 를 변경하면 추정치에 미치는 영향을 고려하지만, 목표에 미치는 영향은 무시함.
- 따라서 부트스트래핑 방법은 실제로 진정한 경사하강법 사례가 아니며, 경사의 일부만 포함되므로 Semi-gradient 방법이라고 한다.
- $v_\pi (S_t)$ 의 부트스트래핑 추정 (9.7) 에서 목표가 $U_t$ 로 사용되는 경우 동일한 보장을 얻지 못한다.
- Semi-gradient (bootstrapping) methods 의 장점
- Semi-gradient (bootstrapping) 방법은 gradient 방법만큼 견고하게 수렴하지는 않지만, 다음 섹션에서 설명하는 선형 사례와 같은 중요한 경우 안정적으로 수렴한다.
- 6장과 7장에서 살펴본 것처럼 일반적으로 훨씬 더 빠른 학습을 가능하게 한다.
- 에피소드가 끝날 때까지 기다리지 않고도 학습이 지속적이고 온라인으로 이루어질 수 있다.
- Semi-gradient TD(0) 의 psuedo code
- 목표값 : $U_t \doteq R_{t+1} + \gamma \hat{v} (S_{t+1},w)$

- t 번째 학습 예제의 목표값을 $U_t \in \mathbb{R}$ 로 정의하면, $S_t \mapsto U_t$ 가 되며, 이때 $v_\pi (S_t)$ 의 참 값은 될 수 없지만, 임의의 근사치일 수는 있다.
- State Aggregation (Chat GPT 검색내용)
- 강화학습에서 Function Approximation을 사용하는 방법 중 하나로 “State Aggregation”이라는 기법이 있다.
- 이 방법은 상태 공간(state space)을 더 작은 그룹으로 나누는 것을 의미
- 각 그룹은 하나의 상태로 취급되며, 이 방법은 연속적인 상태 공간을 이산적으로 변환하여 함수 근사를 적용할 때 유용
- 주요 특징과 원리
- 상태 그룹화 (State Aggregation): State Aggregation은 상태 공간을 작은 그룹 또는 상태 집합으로 나누는 프로세스. 연속적인 상태를 몇 가지 이산적인 상태로 집계하는 것과 유사
- 상태 유사성: 유사한 특성 또는 관찰을 갖는 상태들이 동일한 그룹으로 집계. 이러한 유사성은 도메인 지식 또는 경험에 근거하여 결정
- 함수 근사 적용: 이제 상태 그룹화를 통해 작은 상태 집합을 얻었으므로, 각 그룹에 대한 가치 함수를 추정할 수 있음.
- Function Approximation 기법 중 하나인 선형 함수 근사(linear function approximation) 또는 비선형 함수 근사를 사용하여 각 그룹의 가치 함수를 근사
- 업데이트 규칙: 상태 그룹화를 사용하면 상태 공간이 단순화되므로 각 그룹의 가치 함수 업데이트가 빨라질 수 있음. 에이전트는 각 상태 그룹의 가치 함수를 개별적으로 업데이트함.
- 함수 근사 오류: 그러나 이런 단순화는 정보 손실을 의미하기도 한다. 각 상태 그룹 내에서 상태의 차이나 다양성을 잃을 수 있음. 따라서, State Aggregation을 사용할 때 어떤 정보 손실이 발생할 수 있음을 염두에 두어야 한다.
- 주의점
- State Aggregation은 강화학습에서 상태 공간이 커서 함수 근사를 적용하기 어려운 경우 유용한 방법 중 하나이다.
- 그러나 주의해야 할 점은 그룹화 과정에서 상태 유사성을 올바르게 판단하고, 정보 손실을 최소화하도록 설계해야 한다는 것이다.
- 강화학습에서 Function Approximation을 사용하는 방법 중 하나로 “State Aggregation”이라는 기법이 있다.
- 예제 9.1: State Aggregation on the 1000-state Random Walk
- 문제의 가정
- 1000 개의 상태를 가진 random walk (예제 6.2, 예제 7.1 참고) 문제를 가정한다.
- 상태 : 왼쪽에서 오른쪽으로 1 부터 1000까지 넘버링된 상태, 모든 에피소드는 중앙 (상태 500) 에서 시작
- 상태 전이 : 현 상태 값에서 좌측 100 개, 우측 100개의 상태 내의 값 (전이 확률은 모두 동일)
- 현 상태가 끝쪽에 가깝다면, 100 개의 이웃 상태보다 더 적은 상태가 있을 것이고, 이 경우 종료 상태에 확률이 합산된다.
- 상태 1에서 왼쪽으로 이동해 종료될 확률 (상태 0) : 0.5
- 상태 950 에서 오른쪽이로 이동해 종료될 확률 (상태 1001) : 0.25
- 왼쪽 상태 (0) 에서 끝날 경우 보상은 -1, 오른쪽 상태 (1001) 에서 끝날 경우 보상 +1, 기타 다른 상태에서의 보상은 0
- 결과의 해석
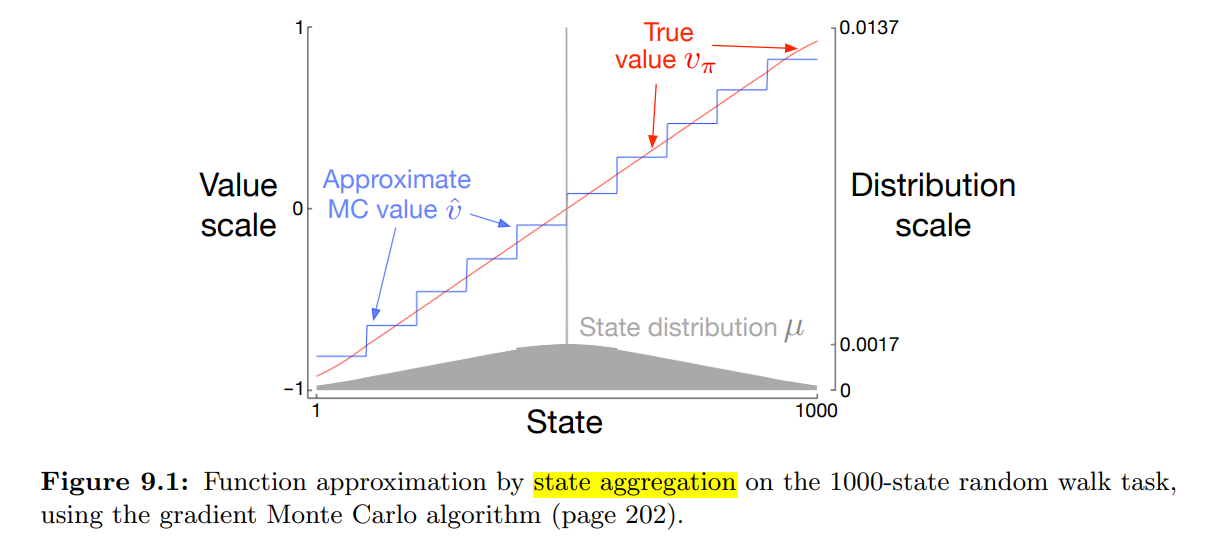
- Figure 9.1 은 이 작업의 참 가치 함수 $v_\pi$ 를 보여준다.
- 이것은 거의 직선이지만, 종료상태 옆 마지막 100 개의 상태에서 수평으로 굽는 형상이다.
- 또한 state aggregation 을 한, gradient Monte-Carlo 알고리즘을 통한 최종 근사 가치함수를 보여준다.
- 100000 에피소드, step size $\alpha = 2 \times 10^{-5}$
- state aggregation 은 1000 개의 상태에서 100개의 상태 묶음 10개 그룹으로 진행 (1-100, 101-200, …)
- 계단 형태의 결과는 전형적인 state aggregation 의 효과이다.
- 각 그룹에서 근사 가치는 상수이며, 하나의 그룹에서 다음 그룹으로 이동 시 이 상수 값이 급격히 변한다.
- 이 근사 값은 $\overline{VE}$ 의 전역 최소값 (9.1) 과 가깝다.
- 근사값의 일부는 상태 분포 $\mu$ 에 영향을 받게 된다.
- 예를 들어 가장 극단의 값 (1) 보다 가장 왼쪽 그룹 중 상태 (100) 이 3배 이상 더 강한 가중치가 부여된다.
- 따라서 그룹에 대한 추정치는 상태 (1) 의 참 값보다 상태 (100) 의 참 값 쪽으로 편향되게 된다.
- Figure 9.1 은 이 작업의 참 가치 함수 $v_\pi$ 를 보여준다.
- 문제의 가정
- Stochastic Gradient Descent (SGD) : 확률적 경사하강법
- Linear Methods
- 가치함수가 가중치에 대해 선형인 경우
- 함수 근사의 가장 중요한 특수 사례 중 하나는 근사함수 $\hat{v} (\cdot , \textbf{w} )$ 가 가중치 벡터 $\textbf{w}$ 에 대해 선형함수인 경우이다.
- 모든 상태에 대응하는, $\textbf{w}$ 와 동일한 수의 구성요소를 가진, 실수 값 벡터 $\textbf{x} (s) \doteq (x_1(s), x_2(s), …, x_d(s))^\top$ 가 있다.
- 이때, 선형 근사 상태-가치 함수는 $\textbf{w}$ 와 $\textbf{x} (s)$ 의 내적으로 구한다.

- 이러한 경우, 근사가치함수는 가중치에 대해 선형이다, 혹은 선형이다 라고 표현한다.
- feature vector
- 벡터 $\textbf{x} (s)$ 는 상태 s의 feature vector 라 한다.
- $\textbf{x} (s)$ 의 각각의 구성요소 $x_i (s)$ 는 $x_i : \mathcal{S} \to \mathbb{R}$ 이다.
- 선형 방법에서 feature 는 근사함수 세트에서 선형 기반을 형성하므로, basis function (기저함수) 가 된다.
- 즉, 각각의 feature 가 각각의 차원을 이룬다.
- d-dimensional feature vector 를 생성하는 것은 d basis function 을 선택하는 것과 같다.
- features 들은 많은 서로 다른 방식으로 정의되며, 우리는 다음 장에서 몇 가지 가능성에 대해 다룬다.
- 벡터 $\textbf{x} (s)$ 는 상태 s의 feature vector 라 한다.
- 선형 가치근사함수와 SGD
- 선형 가치근사에서 SGD 업데이트를 사용하는 것은 자연스럽다.
- $\nabla \hat{v}(s,\textbf{w}) = \textbf{x}(s)$
- 이는 선형 근사 상태-가치 함수가 $\textbf{w}$ 와 $\textbf{x} (s)$ 의 내적으로 구하기 때문임.
- 그러므로 선형 케이스의 경우 SGD 업데이트 (9.7) 가 간단한 형태로 바뀌게 된다.
- $w_{t+1} \doteq w_t + \alpha [ U_t - \hat{v}(S_t,w_t) ] \textbf{x} (S_t)$
- 매우 간단하기 때문에 선형 SGD 사례는 수학적 분석에 가장 유리한 사례 중 하나이다.
- 모든 종류의 학습 시스템에 대한 거의 모든 유용한 수렴 결과는 선형(또는 더 간단한) 함수 근사 방법에 대한 것이다.
- (이 주장은 선형 가치 함수 근사가 간단하면서도 많은 문제에서 효과적으로 동작한다는 아이디어를 강조한 것입니다. 하지만 모든 문제에 대해 선형 근사가 항상 최적인 것은 아닙니다. 일부 문제에서는 더 복잡한 함수 근사가 필요할 수 있습니다.)
- 선형의 경우 단 하나의 최적값 (혹은 최적값의 한 세트) 만 있으므로 지역최적값이나 전역최적값에 수렴하는 것이 자동적으로 보장된다.
- 즉, 근사함수가 선형인 경우 $\frac{1}{2} [ v_\pi(s) - \hat{v}(s,w) ]^2$ 오차 값이 볼록한 형태를 가지고 하나의 최적값이 존재하게 된다.
- 선형 가치근사에서 SGD 업데이트를 사용하는 것은 자연스럽다.
- 선형 가치함수근사와 Gradient Monte Carlo 알고리즘의 경우
- 예를 들어 이전 섹션에서 제시된 gradient Monte Carlo 알고리즘은 시간이 지남에 따라 $\alpha$ 가 감소하면 선형함수근사 하에 $\overline{VE}$ 의 전역최적으로 수렴한다.
- 선형 가치함수근사와 semi-gradient TD(0) 알고리즘의 경우
- 마찬가지로 앞서 다룬 semi-gradient TD(0) 도 선형함수근사 하에 수렴하나, SGD 의 일반적 결과와는 다르다.
- 가중치 벡터는 전역최적이 아닌 지역최적에 수렴한다. (특히 연속적인 케이스에서 중요)
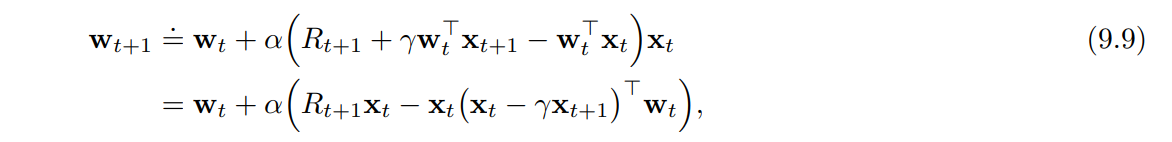
- 여기에서 우리는 축약 표기 $\textbf{x}_t = \textbf{x}(S_t)$ 를 사용한다.
- 시스템이 정상 상태에 도달하면 어떠한 $\textbf{w}_t$ 에 대해서도 다음 가중치 벡터를 아래와 같이 구할 수 있다.


- 위의 값을 TD fixed point 라고 한다.
- 선형 semi-gradient TD(0) 는 이 지점으로 수렴한다.
- 위 수식에 대한 이해 (Chat GPT 로 정리한 내 생각)
- 즉 Semi-gradient 방식은 업데이트 식의 타겟에 학습 중인 가중치 벡터 $w$ 가 포함되어 수렴이 늦어지나
- 근사함수가 선형일 경우 현재 목표 $w_{TD}$ 를 아래의 요소로 계산하여 구할 수 있으므로
- $\textbf{x}_t$
- $\textbf{x}_{t+1}$
- $R_{t+1}$
- 위 요소에 따라 $w_{TD}$ 의 값이 바뀔 수 있으나 학습해야 할 파라미터 $w$ 가 목표에 없으므로 더 빠르고 안정적인 수렴이 가능하다는 이야기.
- Proof of Convergence of Linear TD(0)
- 아래의 내용을 이해해보려 하였으나, 너무 복잡하여 본문 내용을 붙여넣는 것으로 갈음한다.


- 마지막으로, 이것은 TD(0) 알고리즘이 수렴할 때 가중치 벡터 $w_{TD}$ 에서의 에러가 전체 상태 공간에서의 최적 에러 $w^*$ 에서의 에러에 대한 한계로 나타나며, $\gamma$ 가 충분히 작을 때 $w_{TD}$ 의 에러가 최적 에러에 근접함을 보여준다.
- $\overline{VE}(w_{TD}) \leq \frac{1}{1-\gamma} \min_w \overline{VE}(w)$
-
가능한 가장 작은 에러 값에 대한 $\overline{VE}$ 의 경계치

- Chat GPT 로 내가 확인한 내용
- $w_{TD}$ 는 부트스트래핑으로 얻은 특정 상태에 대한 추정값으로, 실제 값과는 오차가 있을 수 있다.
- $w$ 는 $w_{TD}$ 와는 별개로, 전체 상태에 대한 가중치 값을 학습하는 것으로, 각 상태의 $w_{TD}$ 로부터 추정된 값과 $w$ 로 계산된 값 사이의 오차 합을 최소화하려고 노력한다.
- 부등식 $\overline{VE}(w_{TD}) \leq \frac{1}{1-\gamma} \min_w \overline{VE}(w)$ 는 $\gamma$ 값이 충분히 작을 때 $w_{TD}$ 의 각 상태에 대한 평균 에러가 전역최적 $w$ 의 평균 에러 값으로 계산된 경계 영역보다 작음을 보장한다는 내용이다.
- 즉, TD 방법은 $\gamma$ 값이 1에 가까워지면, 점근 성능에 상당한 잠재적 손실이 있을 수 있으나, 종종 몬테카를로 방법에 비해 분산이 크게 줄어들어 더 빠르게 수렴할 수 있다.
- 9.14 와 유사한 경계는 다른 정책 부트스트래핑 방법에도 작용되며, Sarsa(0) 와 같은 방법이나 에피소드 작업과 같은 방식도 유사한 경계값이 있음.
- 보상, 기능, step-size 매개변수 감소에 대한 몇 가지 기술적 조건이 있으나 여기에서는 생략함.
- 이러한 수렴 결과에서 중요한 것은 상태가 정책 분포에 따라 업데이트된다는 것이다.
- 다른 업데이트 분포의 경우 함수 근사를 사용하는 부트스트래핑 방법은 무한대로 발산할 수 있다.
- 이에 대한 예와 가능한 해결 방법은 11장에서 다룬다.
- Chat GPT 로 내가 확인한 내용
- 마찬가지로 앞서 다룬 semi-gradient TD(0) 도 선형함수근사 하에 수렴하나, SGD 의 일반적 결과와는 다르다.
- 예제 9.2 : Bootstrapping on the 1000-state Random Walk
- 이 장에서 관찰한 내용 중 일부를 설명하기 위해 1000개 상태의 랜덤 워크의 예제를 사용 (State aggregation + 선형함수근사)
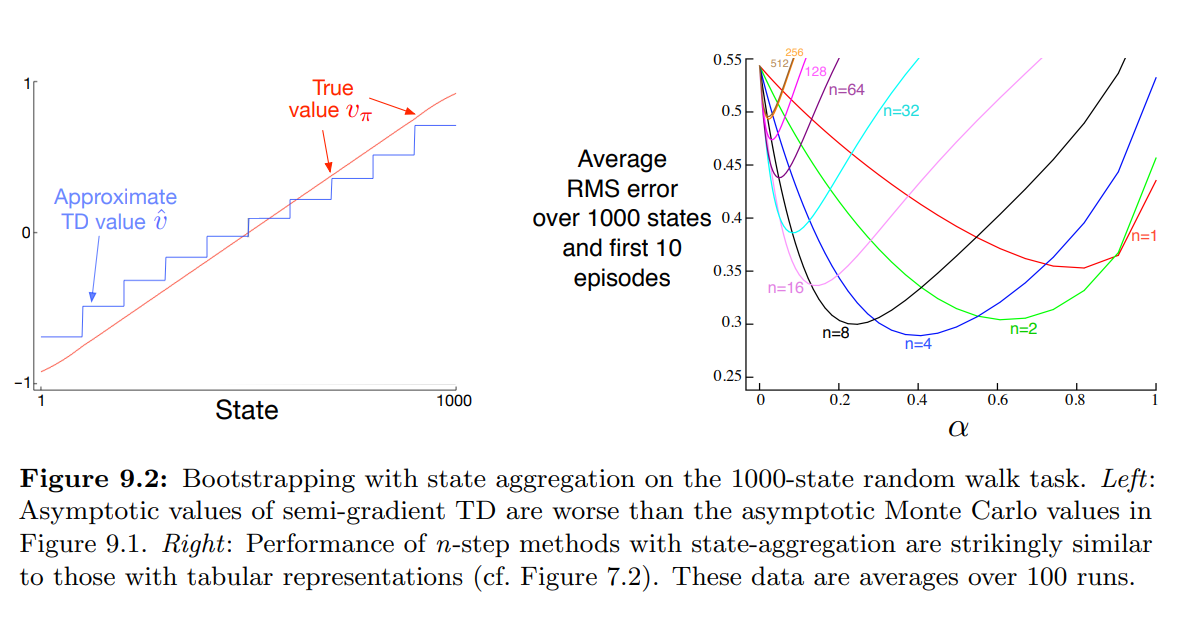
- 왼쪽 패널은 예제 9.1 과 동일한 State aggregation 을 사용, Semi-gradient TD(0) 에 의한 학습된 최종 값 함수를 보여줌
- TD 근사가 몬테카를로 근사보다 실제 값에서 더 멀다는 것을 알 수 있음
- 오른쪽 패널은 그림 7.2 (n-step semi-gradient TD + state aggregation) 와 유사한 결과를 보여준다.
- 함수근사를 한 것과, tabular 계산을 한 것의 유사성을 보여줌
- semi-gradient n-step TD 알고리즘은 tabular n-step TD 알고리즘에서 semi-gradient 함수 근사를 확장한 것으로 psuedocode 는 아래와 같다.


- 가치함수가 가중치에 대해 선형인 경우
Estimating Value Functions as Supervised Learning
Moving to Parameterized Functions
- Tabular Methods
- 모든 가능 상태를 표현하는 테이블 형태의 저장공간에 각각의 학습 값을 저장하는 형태
- 하지만 실제 세계의 문제들의 경우 이 테이블 저장공간이 추적불가능할 정도로 커지게 된다.
- 로봇이 카메라를 통해 세계를 관찰하는 경우, 모든 가능한 이미지를 저장할 수는 없음.
- 학습목표
- 파라미터화된 함수를 사용하여 근사값을 구하는 법 이해하기
- 선형 가치함수근사의 의미를 설명하기
- tabular 케이스 또한 선형 가치함수근사의 특별한 케이스임을 이해하기
- 가치함수근사를 파라미터화 하는 많은 방법이 있음에 대해 이해하기
-
다양한 형태로 표현가능한 가치 함수
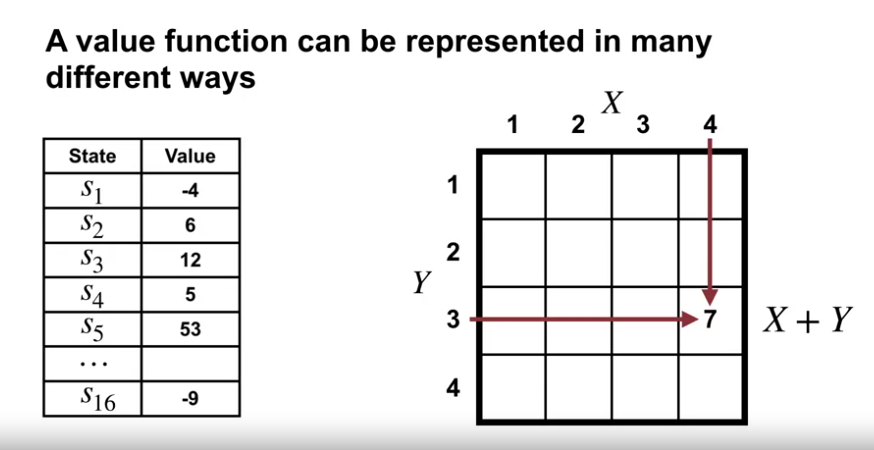
- 좌측은 tabular 형태로 각각의 가치함수값을 가지고 있는 형태
- 각각의 상태에 따라 독립된 값을 테이블에 저장하는 형태 (지금까지 학습한 방식)
- 학습이 진행됨에 따라 테이블에 저장된 값을 업데이트한다.
- 우측은 X 와 Y 좌표 값에 따라 X + Y 가치함수를 가진 형태
- 이론적으로 우리는 상태를 제공받아 실수를 출력하는 어떠한 함수도 사용할 수 있다.
- 하지만 이러한 형태를 가치함수로 사용하기를 원치 않음.
- 이 예측치를 수정할 방법이 없음 (학습할 방법이 없음)
- 좌측은 tabular 형태로 각각의 가치함수값을 가지고 있는 형태
- Parameterized function
- $\hat{v}(s,\textbf{w}) \approx v_\pi (s)$
- $\textbf{w}$ : weights (가중치) - 함수에 변화를 주기 위한 조정이 가능해짐.
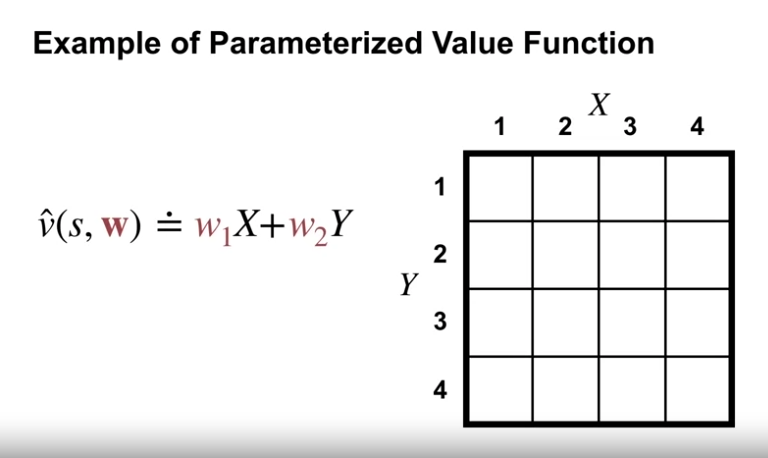
- $\hat{v}$ : 참 가치함수 값을 근사하는 함수의 의미
- $\textbf{w}$ : 함수근사에 대하여 모든 가중치를 파라미터화 한 벡터 값
- 여기에서 우리는 모든 상태에 대한 가치함수 값을 저장하는 것이 아닌, 2개의 가중치만을 저장하게 된다.
- $\hat{v}(s,\textbf{w}) \approx v_\pi (s)$
-
가중치(Weight) 의 변화가 가치함수에 주는 영향

- tabular case 의 경우 하나의 상태값에 영향을 주지만
- Parameterized function 의 경우 가중치 하나를 변경할 경우 복수 개의 상태에 변화를 준다.
-
Linear Value Function Approximation
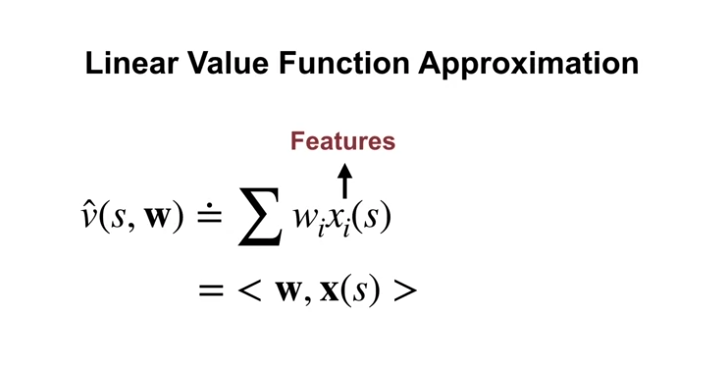
- 가중치와 어떠한 고정된 속성 (feature) 간의 곱의 합
- 위의 식일 간단하게 weight vector $\textbf{w}$ 와 feature vector $\textbf{x} (s)$ 간의 내적 (inner product) 으로 표현한다.
-
Limitations of Linear Value Function Approximation
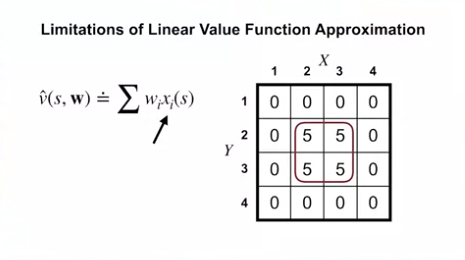
- 위의 linear value function approximation 을 살펴보면 X, Y feature 에 대해서 선형적인 표현만 할 수 있다.
- 만약 참 값이 위의 그림과 같다면 X, Y feature 에 대한 선형 함수로는 표현할 방법이 없다.
- 외각의 0 을 표현하기 위해서는 $W_1$ 과 $W_2$ 가 0이 되어야만 한다.
- 그렇게 된다면 내부의 5를 표현할 방법이 없다.
- 그러나 우리가 반드시 X, Y 값을 features 로 사용할 필요는 없다.
- 즉, Linear value function 은 좋은 특징(features) 값을 가지는 것이 중요하다.
- 특징(features) 을 정의하는 데 다양한 효과적인 방법들이 있다.
- 즉, Linear value function 은 좋은 특징(features) 값을 가지는 것이 중요하다.
-
Tabular case 를 linear function 으로 표현하는 방법

- 각각의 상태를 feature 로 정의한다.
- 이에 대응하는 가중치 값과의 내적을 구하면, 왼쪽의 Tabular case 와 동일한 연산이 된다.
-
Nonlinear Function Approximation
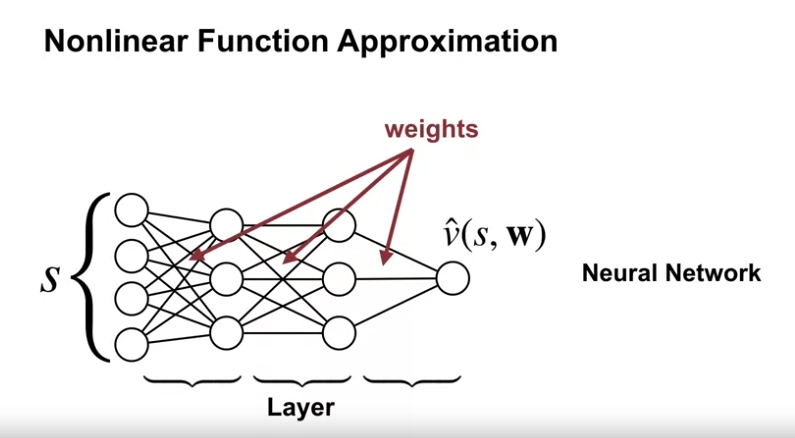
- 신경망 방식 또한 비선형 가치근사 방법 중 하나이다.
- 이 또한 parameterized function 중 하나이다.
- 상태 S 가 실제 가중치 값들 $\textbf{w}$ 를 통과하며 $\hat{v}(s, \textbf{w})$ 의 연산을 하게 된다.
Generalization and Discrimination
- Generalization 에 대해
- 함수 근사에서 가장 중요한 고려사항은 어떻게 상태들을 일반화 (Generalize) 할 것인지 이다.
- Generalization 의 예
- 어떤 사람이 특정한 자동차를 운전하는 방법을 배울 경우, 다른 자동차의 운전 방법을 배울 때 처음부터 배우지 않는다.
- 혹은 다른 도로에서 운전하거나, 비 오는 도로에서 운전한다고 처음부터 배우지 않는다.
- 학습목표
- generalization (일반화) 와 discrimination (차별) 의 의미 이해하기
- generalization (일반화) 의 혜택 이해하기
- 가치 근사에서 왜 generalization (일반화) 와 discrimination (차별) 모두가 필요한지 설명하기
- Generalization
- 직관적 의미 : 특정한 상황에서의 지식을 적용하여 광범위한 상황에서의 결론을 도출하는 것
- 정책 평가에서의 의미 : 하나의 상태에서 추정값의 업데이트가 다른 상태의 값에도 영향을 주는 것
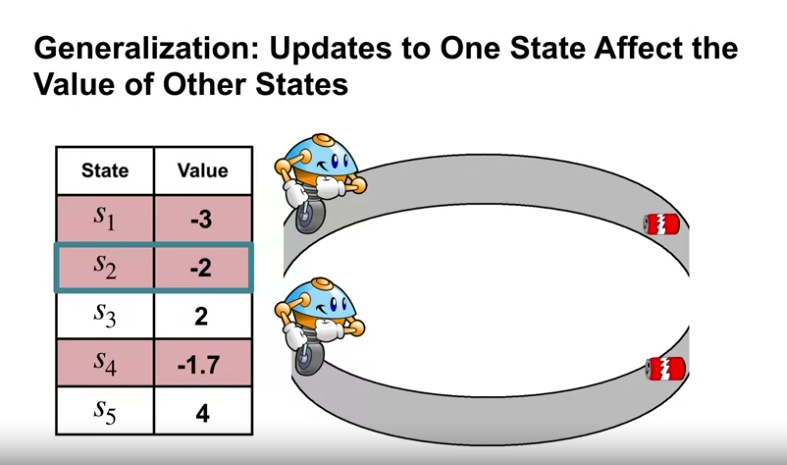
- 위의 그림처럼 가령 비슷한 시간이 소요되는, 비슷한 거리의 캔을 수거하러 가는 경우 센서에 의해 다른 값이 읽히더라도 비슷한 값이 도출될 수 있다.
- 이러한 경우 위의 두 상태에 대해 가치함수의 일반화를 하길 원한다.
- 일반화를 통해 더 빠른 학습의 진행이 가능하다. (아직 방문하지 않은 상태에 대해서도 업데이트가 가능함)
- Discrimination
- 두 개의 상태를 구분하여 두 개의 상태가 다르도록 만드는 능력
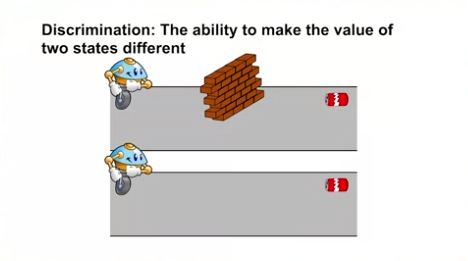
- 거리가 같더라도 벽 뒤에 있는지, 벽이 없는지에 따라 상태를 구분해야 한다.
- 따라서 비슷한 거리에 있는 캔에 대해 상태를 일반화하는 것도 중요하나, 다른 정보에 따라 상태를 구분하는 것도 중요하다.
-
일반화와 구분에 따른 카테고리화
- Tabular Methods : 구분은 뛰어나나 일반화는 전혀 못함. 각 상태에 대해 독립적인 학습을 진행함.
- Aggregate All States : 모든 상태를 똑같은 상태로 판단. 상태에 대한 학습이 불가함
- $*$ (●:현실적인 목표) : 좋은 구분과 좋은 일반화를 달성한 상태로, 비슷한 상태끼리 학습을 같이 진행하여 빠른 학습을 하고, 상태간 구분을 하여 정확히 근사를 하는 상태
- 예를 들어 비슷한 상태그룹을 나타내는 feature 를 표기한다.
-
Generalize 방법에 대해
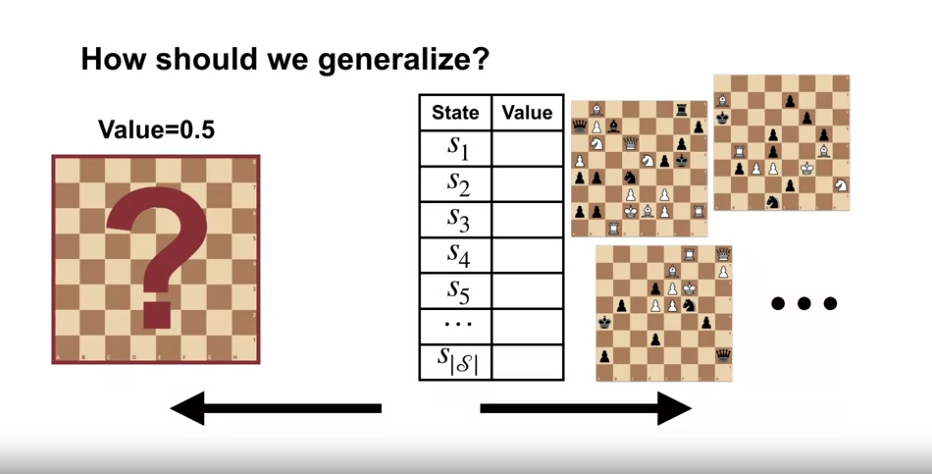
- 좌측은 극단적인 Generalize 로 모든 체스게임 상태를 동일한 상태로 보고, 승률을 0.5 로 책정한 경우 (안좋은 예측값)
- 우측은 Tabular Case 의 경우로 모든 경우의 수에 대해 승률을 책정한 경우 (경우의 수가 너무 많아 불가능)
- 우리는 이 사이의 무언가를 원한다.
- 비슷한 승률 (비슷한 상태) 끼리의 그룹화는 어려운 질문이다.
- 이것은 우리의 알고리즘 성능에 지대한 영향을 미치며, 머신러닝과 강화학습의 중심 화제이다.
Framing Value Estimation as Supervised Learning
- 학습목표
- 어떻게 가치 측정이 지도학습 문제에 포함될 수 있는지 이해하기
- 모든 가치근사방식이 강화학습에 잘 적용될 수 없다는 점을 식별하기
-
Supervised learning
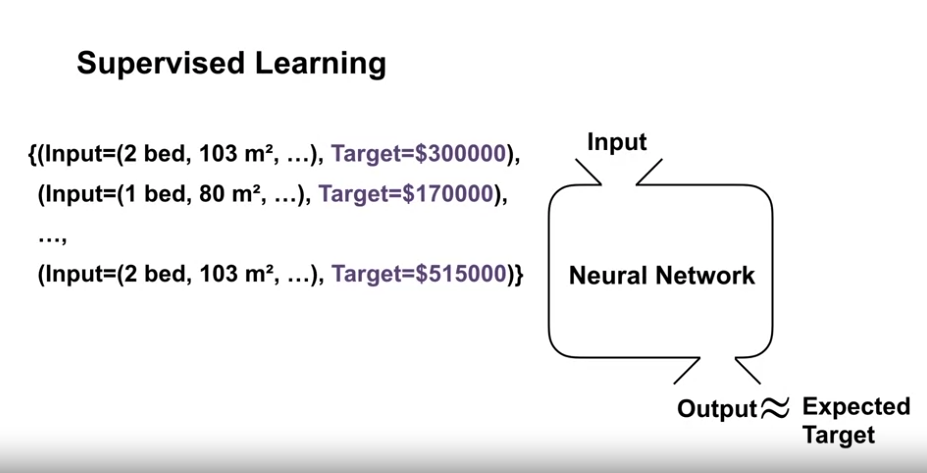
- 지도학습도 입력 값과 목표 값을 이용해 함수를 근사시키는 과정은 동일하다.
- 학습 세트에 없는 입력값에 대해서, 일반화를 통해 실 가치와 유사한 값을 얻길 원한다.
- 이러한 parameterized function 은 여러 형태로 표현될 수 있는데, 그 중 하나가 신경망이다.
-
Monte Carlo 방식과 Supervised Learning 의 유사성
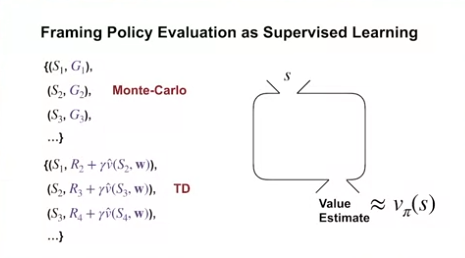
- Policy Evaluation 에 있어서, Monte Carlo 는 샘플의 리턴값을 이용하여 가치 함수를 추정하는 방식이다.
- 이 또한 입력값이 상태, 목표 값이 리턴 값인 지도학습의 일환으로 볼 수 있다.
- 또한 모든 상태에서 함수가 참 값과 유사한 예측값을 출력하기를 원한다.
- 이는 TD 또한 마찬가지이다.
- Policy Evaluation 에 있어서, Monte Carlo 는 샘플의 리턴값을 이용하여 가치 함수를 추정하는 방식이다.
-
모든 가치근사 방식이 강화학습에 잘 적용될 수 없는 이유
- 온라인 업데이트
- 에이전트가 환경과 상호작용을 하면서 계속 새 데이터를 만드는 경우 (즉, 처음부터 전체데이터에 접근 가능한 Offline Learning 과 차이가 있음)
- 함수 근사를 사용할 때, 해당 방식이 온라인 환경에서 잘 적용될 수 있는지를 생각해 봐야 한다.
- 어떠한 근사 방법은 고정된 배치 데이터를 사용해야 하거나, 시간적으로 상관된 데이터 (강화학습은 언제나 상관되어 있다.) 에 맞지 않는 경우가 있다.
- 부트스트래핑
- 타겟 값이 현재의 추측값과 연관이 있을 경우
- 계속적으로 타겟 값이 변동되는 경우
- 온라인 업데이트
The Objective for On-policy Prediction
The Value Error Objective
- 학습목표
- 정책 평가를 위한 평균제곱오차 (mean squared value error) 의 목표 이해
- 목표에서 상태 분포 (state distribution) 의 역할을 설명하기
- An Idealized Scenario
- 예를 들어 모든 상태에 대한 참 값을 알 수 있는 상태라고 가정하자.
- ${(S_1, v_\pi(S_1)), (S_2, v_\pi(S_2)), (S_3, v_\pi(S_3)), …}$
- 우리는 이 참 값과 최대한 유사한 값을 출력할 수 있는 근사 함수를 찾아야 한다.
- $\hat{v}(s,\textbf{w}) \approx v_\pi(s)$
- 하지만 위 근사함수가 모든 상태에서 참 값과 동일한 값을 출력할 수는 없다.
- 우리는 가중치 $\textbf{w}$ 값을 조절하여 최대한 좋은 결과를 얻고자 한다.
- 우리는 어떠한 측정치를 이용하여 우리의 예측을 보다 정확하게 조절할 필요가 있다.
- 예를 들어 모든 상태에 대한 참 값을 알 수 있는 상태라고 가정하자.
- The Mean Squared Value Error Objective
- 문제의 가정
- 선형 가치근사함수 $\hat{v}$
- 상태는 1차원에 연속적이라고 가정

- Squared Value Error
- $[v_\pi(s) - \hat{v}(s, \textbf{w} )]^2$
- 참 값과 추정 값 간의 오차를 측정할 수 있는 전통적인 방법
- 문제는 하나의 상태에서 오차가 준다면, 다른 상태에서 오차가 늘어날 수도 있다는 점이다.
- Sum of Squared Value Error
- $\sum_s [v_\pi(s) - \hat{v}(s, \textbf{w}) ]^2$
- 모든 상태에서의 오차 합을 측정
- 하지만 과연 모든 상태가 서로 같은 중요도를 가진다고 볼 수 있을까?
- Sum of Mean Squared Value Error
- $\sum_s \mu(s) [v_\pi(s) - \hat{v}(s, \textbf{w}) ]^2$
- $\mu(s)$ : 해당 정책 하에 s 상태에 방문한 빈도 수를 전체 빈도수 대비 분수로 나타낸 것
- 많이 방문한 상태의 에러 값에 더 많이 집중하고, 드물게 방문한 상태의 에러값에 덜 신경 쓰는 것
- 해당 값은 확률분포 값이다.
- 문제의 가정
- Adapting the Weights to Minimize the Mean Squared Value Error Objective
- $\overline{VE} = \sum_s \mu(s) [v_\pi(s) - \hat{v}(s, \textbf{w})]^2$
- 우리는 가중치 $\textbf{w}$ 를 조정하여 Mean Squared Value Error 값을 최대한 작게 만드는 것이 목적이다.
- 이 Objective 를 VE bar 라고 한다.
- 함수 근사를 이용한 정책의 평가는 특정한 목표값을 정의해야 한다.
- Mean Squared Value Error 는 이러한 목표값 중 하나이다.
Introducing Gradient Descent
- 학습목표
- 경사하강법의 개념을 이해한다.
- 경사하강법이 고정된 한 지점으로 수렴하는 것을 이해한다.
-
Recap : Learning Parameterized Value Functions
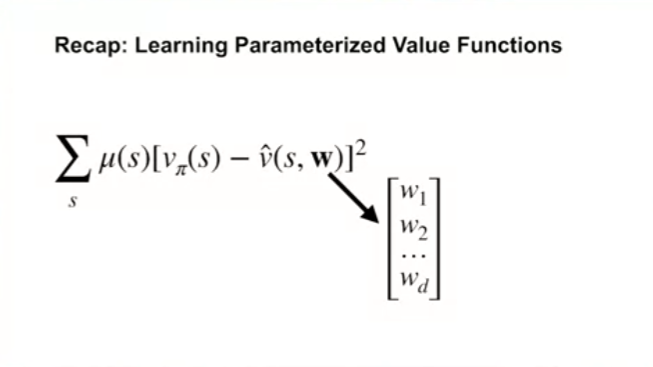
- 가중치 $\textbf{w}$ 는 실제 실수 값들로 이루어져 있다.
- 위의 연산을 보면, 가중치의 변화는 많은 상태에 영향을 줄 수 있다.
- 우리의 목표는 전체 에러값 (Overall value error) 의 최소화이다.
-
Understanding Derivatives (미분 이해하기)
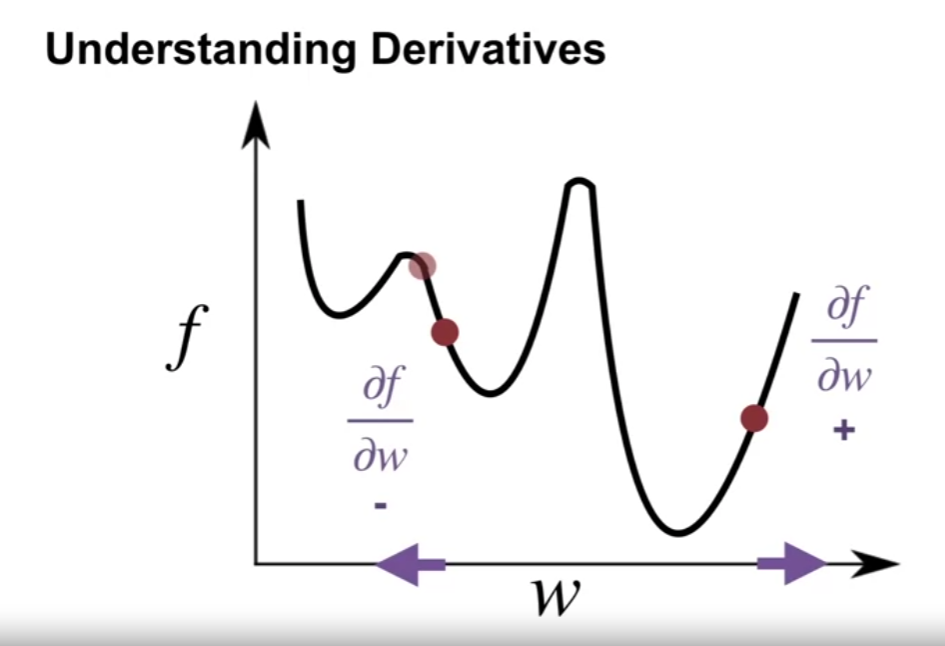
- $f$ : function, 여기에서는 위 value error 로 이해
- $W$ : 가중치의 스칼라 파라미터로 이해
- 여기에서 미분 값으로 $W$ 값의 지역적 변화에 대해 $f$ 값을 증가시킬지 감소시킬지를 알 수 있다.
- 미분 값의 음수, 양수의 여부로 $W$ 포인트에서 $f$ 증가, 감소에 대해 판단
- 미분 값의 절대값 크기로 $W$ 포인트에서의 경사 (얼마나 급변하는지) 에 대해 판단
- 여기에서 미분 값의 기울기 방향으로 $W$ 를 이동시키는 것은 $f$ 의 값을 증가시키는 방향으로 이동하는 것임
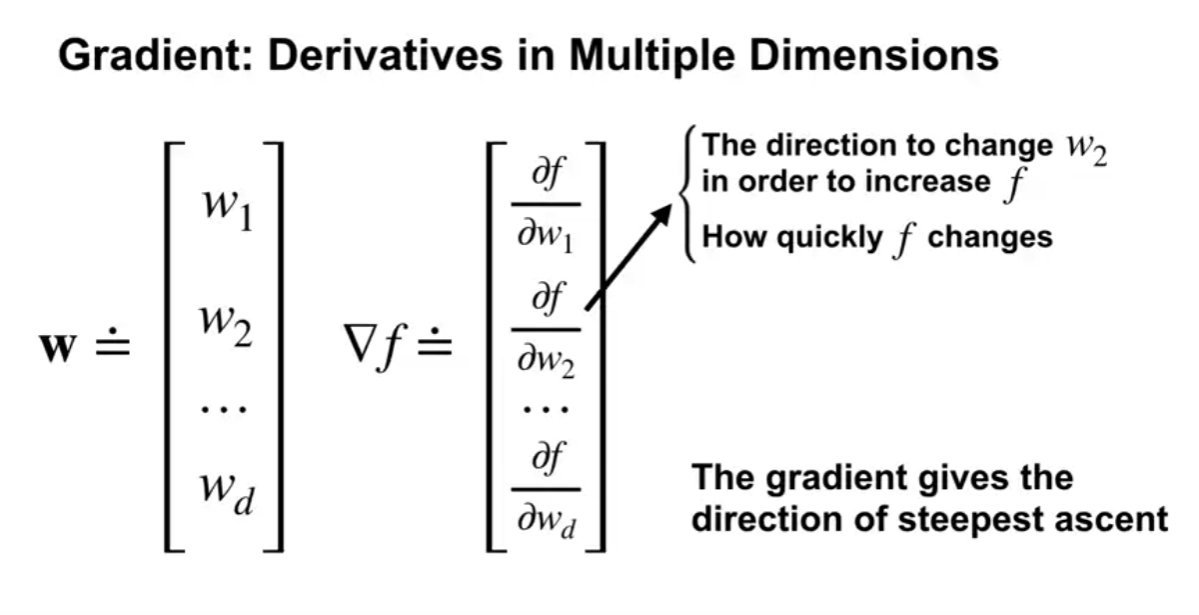
- $\textbf{w}$ 의 벡터 요소의 수 (차원) 에 따라 여러 차원의 미분값이 존재한다.
- 이 각각의 차원들에 대해서도 위의 규칙이 통용된다.
-
Example : Gradient of a Linear Value Function

- 이전에 다뤘듯, 선형가치근사함수에서의 가치함수값은 단순 가중치와 상태 feature vector의 내적이었다.
- 이 때, feature vector 는 가중치와는 독립적인 값이므로, 미분 값이 해당 상태의 feature vector 그 자체가 되게 된다.
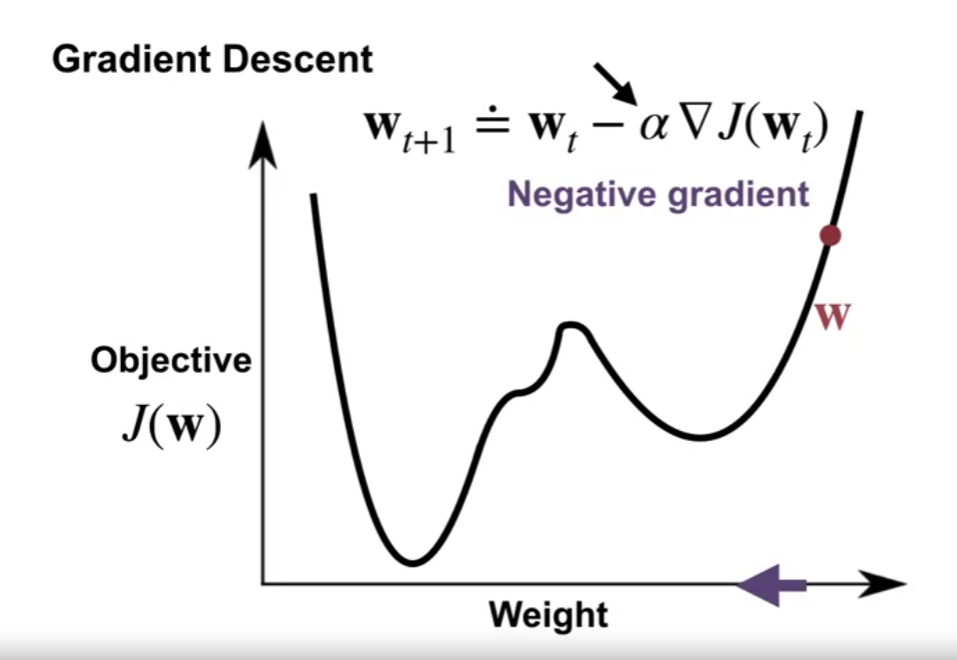
- 목표 값은 $\textbf{w}$ 에 대한 함수이다.
- $\hat{v}$ 가 $\textbf{w}$ 에 대한 함수이기 때문
- 우리의 목표는 이 함수 값을 최소화 하는 것이다.
- $\alpha$ : 얼마나 움직일지 (step-size) 를 정의. 미분 값은 지역적인 영역에서의 증감만을 보장하기 때문
- 적은 양으로 가중치를 조절하다 보면 Gradient 값이 0이 되는 부분이 있는데 이 부분을 지역최소값 (local minumim) 이라 한다.
- 해당 가중치 $\textbf{w}$ 가 당장의 근처 값보다 낫다는 것을 보여줌. (하지만 최적의 값은 아닐 수 있음)
- Global Minima and Solution Quality
- 전역최적값 (global minimum) $\textbf{w}_*$ 에서의 $\hat{v}$ 값이 반드시 참 값일 필요는 없음. (충족하지 않음)
- $\hat{v} \ne v_\pi$
- 이것은 function parameterization 의 한계이기도 하고, 목표값(objective)의 설정에도 영향을 받는다고 볼 수 있음
- 만약 feature vector 값이 상태와 무관하게 언제나 1이라면, Mean Squared Value Error 목표값을 최소화 하는 근사가치함수 (모든 상태에 대해 평균 값을 제공) 를 찾을 수는 있겠지만 이것이 좋은 가치함수라고 볼 수는 없다. (이 경우는 feature vector 가 잘못 설정된 경우)
- 전역최적값 (global minimum) $\textbf{w}_*$ 에서의 $\hat{v}$ 값이 반드시 참 값일 필요는 없음. (충족하지 않음)
Gradient Monte for Policy Evaluation
- 학습목표
- 경사하강법과 확률적 경사하강법을 사용하여 오차값을 최소화 하는 방법 이해하기
- 가치 추정을 위한 Gradient Monte Carlo 알고리즘의 이해
-
Gradient of the Mean Squared Value Error Objective

- 첫번째로 목표값 (Objective) 의 Gradient 를 찾아야 한다.
- 위의 경우 Mean Squared Value Error 의 Gradient 를 찾아야 한다.
- Mean Squared Value Error : A weighted sum of the squared error over all states.

- Mean Squared Value Error 에 대한 Gradient 를 계산하는 것은 모든 상태에 대한 합, 모든 상태의 확률분포에 대한 계산을 의미
- 일반적으로 실현이 불가능하다.
- 대부분의 경우 분포값 $\mu$ 를 알지 못한다.
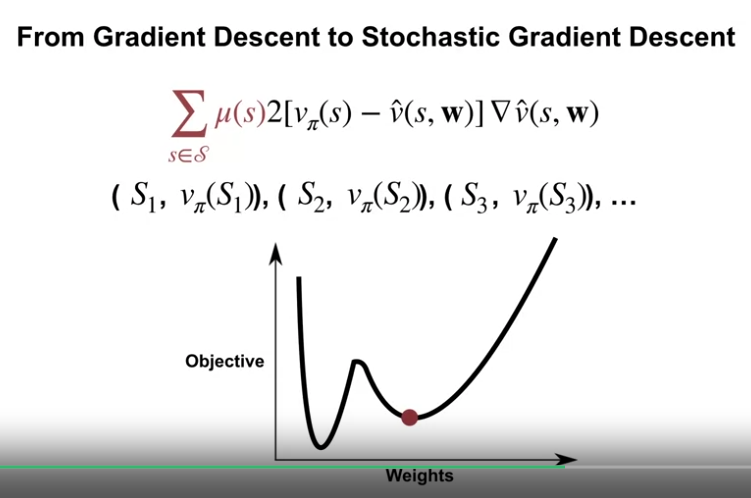
- 이상적인 설정 - $v_\pi$ 에 접근이 가능한 경우
- 명시적으로 $\mu$ 가 없더라도, 정책을 따름으로서 상태를 샘플링할 수 있다.
- 정책을 따르면서 얻은 상태에 대한 가중치의 즉각적인 업데이트가 가능하다.
- 하나의 차원으로 볼 때, 상태 샘플에 따라 에러값이 늘어날 수도 있지만 점진적으로 개선되어간다.
- 위와 같은 업데이트 접근법을 확률적 경사하강법 (Stochastic Gradient Descent) 이라 한다.
- 즉, 확률적이란 모든 상태에 대한 업데이트가 아닌, 정책을 따라 얻은 샘플링된 상태에 대한 업데이트를 한다는 뜻
- 이 확률적 경사하강법은 경사에 대한 노이즈가 있는 근사라고 볼 수 있다.
- 계산비용이 훨씬 저렴함
- 최소값까지 꾸준한 발전을 이룰 수 있음
- 첫번째로 목표값 (Objective) 의 Gradient 를 찾아야 한다.
-
Gradient Monte Carlo

- 위의 Stochastic Gradient Descent 에는 한계점이 있다.
- 우리는 $v_\pi$ 에 접근할 수 없다.
- 이 $v_\pi$ 값을 정책을 따라 얻은 리턴값으로 대체한다. (Monte Carlo 방식)
- 생성된 에피소드 샘플에 대하여 가중치 업데이트를 진행한다.
- 위의 Stochastic Gradient Descent 에는 한계점이 있다.
State Aggregation with Monte Carlo
- 학습목표
- 가치함수의 근사를 위한 state aggregation (상태 집합) 기법 사용법 이해
- state aggregation (상태 집합) 과 함께 Gradient Monte Carlo 방식 적용
-
Random Walk Example
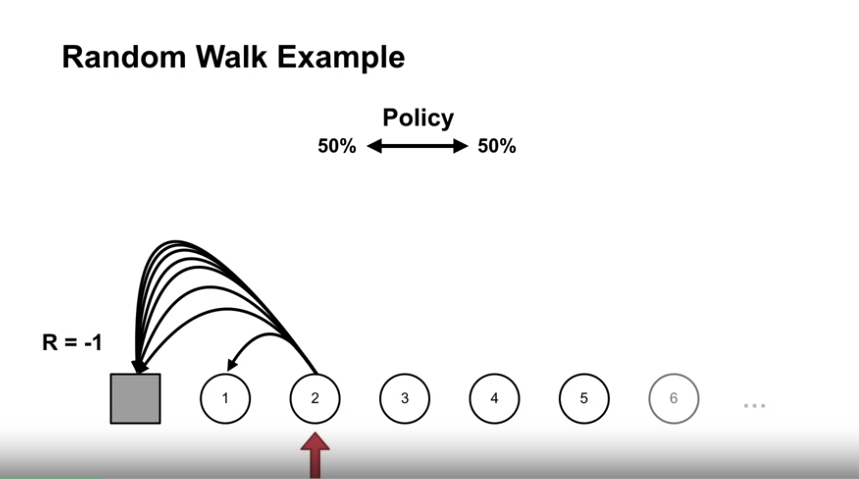
- 문제의 정의
- 좌, 우측에 종료상태, 그리고 1 부터 1000 까지의 상태가 있다.
- 좌측 종료상태에서 보상 -1, 우측 종료상태에서 보상 +1, 그 외의 상태는 보상 0
- 동작은 좌측 혹은 우측으로 100칸까지 이동 가능하며 좌,우 1~100 칸 이동 확률은 uniform random policy 를 따른다.
- 첫 시작 지점은 상태 500에서 시작한다.
- discount gamma 값은 1이다. (할인 없음)
- 문제의 정의
-
State Aggregation

- 몇몇 상태를 같은 상태로 취급하는 기법
- 위의 예시에서 상태가 8개 있는데, 4개의 상태를 같은 상태로 묶어 2개의 상태로 취급하는 기법임.
- 즉, 위의 묶음 중 아무 상태가 업데이트 되어도 나머지 3개의 상태가 같이 업데이트된다.
- State Aggregation 은 linear function approximation 의 일종이다.
- 상태가 많은 경우 학습의 속도가 느려질 수 있는데, 위 기법을 통해 빠르게 학습할 수 있음.
-
How to Compute the Gradient for Monte Carlo with State Aggregation

-
Constructing a State Aggregation for the Random Walk

- 어떻게 집합으로 묶을 것인가?
- State Aggregation 은 상태를 동일 그룹 군으로 묶어 같은 가치 추정을 하도록 만든다.
- 즉, 우리는 상태를 묶을 때 그들의 값이 유사할 것이라고 생각되는 상태들을 그룹군으로 묶어야 한다.
- 그룹이 작다면 보다 더 정확한 결과를 얻을 것이나, 학습 시간이 더 오래 걸린다.
- Random Walk 문제에서는 1부터 1000까지의 상태를 100개 단위의 그룹 군으로 묶어본다.
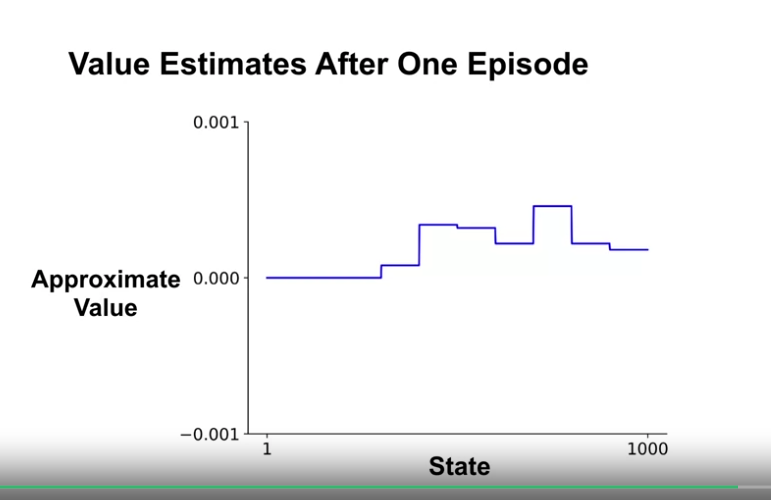
- 첫 에피소드에 대한 해석
- 첫 번째 에피소드는 종료 결과 보상 1을 얻었고, 할인이 없기 때문에 모든 상태에 대한 리턴값은 1이 된다.
- 속하는 그룹의 가중치 값이 모두 업데이트 된다.
- 여러 상태를 오간 뒤 첫번째 에피소드에 대한 가치 추정의 결과는 위 그림과 같다.
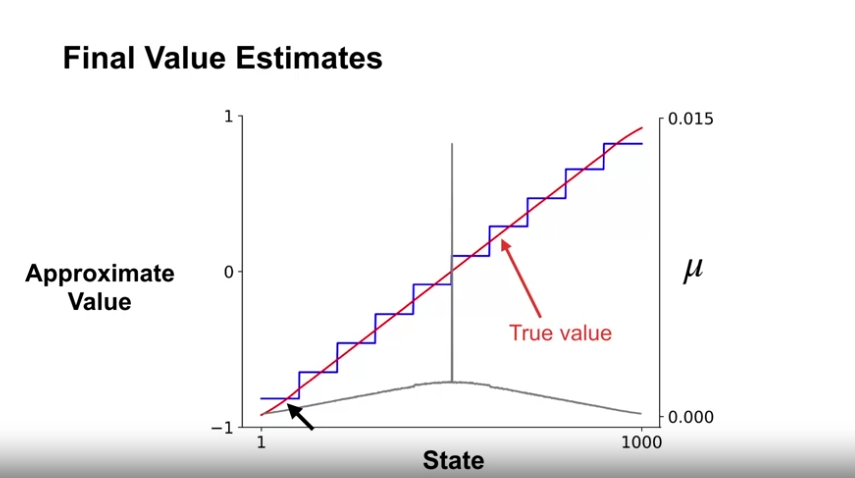
- 최종 에피소드 이후 가치 추정 결과
- 각 상태그룹에 따라 동일한 근사 값을 가지는 것을 볼 수 있음
- 참 값이 근사 값의 중앙을 관통하는 것은, 상태의 확률분포 (극단지점의 상태보다 그렇지 않은 상태의 분포가 더 크다) 의 영향이다.
- 어떻게 집합으로 묶을 것인가?
The Objective for TD
Semi-Gradient TD for Policy Evaluation
- 학습목표
- 함수 근사를 위한 TD update 의 이해
- 가치 추정을 위한 Semi-gradient TD(0) 알고리즘의 개요
-
Gradient Monte Carlo 와의 비교

- Gradient Monte Carlo 에서는 리턴값 $G_t$ 를 사용하며 이는 편향되지 않은 값이기에 가중치가 지역 최적값에 수렴한다.
- 꼭 리턴값이 아니더라도 다른 타겟을 사용할 수 있으며, 이 값이 편향되지 않다면 수렴을 보장한다.
- TD 방식에서는 현재 가치 추정값을 타겟으로 하기에 값이 편향된다.
- 추정값이기에 참 가치함수와는 값이 다름.
- 그렇기에 해당 알고리즘은 에러 값이 지역 최소값에 수렴한다고 보장할 수 없다.
- Gradient Monte Carlo 에서는 리턴값 $G_t$ 를 사용하며 이는 편향되지 않은 값이기에 가중치가 지역 최적값에 수렴한다.
- TD target 의 이점
- 샘플의 리턴 값보다 분산이 작아 더 빠르게 수렴한다.
- TD target 의 이점 (Chat GPT)
- 계산 효율성: 함수 근사를 사용한 TD 업데이트는 매우 큰 상태 공간에서도 적용할 수 있다. 대규모의 상태 공간을 전체적으로 계산하는 것보다 훨씬 효율적임.
- 활용 가능한 데이터: 실제 상황에서는 종종 완벽한 정보가 제공되지 않는다. 편향된 추정값이라도 현재 사용 가능한 정보를 기반으로 한 업데이트는 여전히 유용할 수 있다.
- 탐색적인 측면: 편향된 추정값을 사용하는 것은 다양한 상황을 탐색하고 경험하는 데 도움을 줄 수 있다. 이는 종종 실제 환경에서 더 나은 행동을 선택하는 데 도움이 될 수 있다.
- 일반화 가능성: 함수 근사를 사용한 TD 업데이트는 일반화 가능성을 가질 수 있다. 이는 일부 편향된 추정값이라도 일반적인 상황에서 적용 가능한 모델을 생성할 수 있다는 것을 의미함.
-
TD is a semi-gradient method

- TD 의 경우 업데이트의 목표 타겟값이 TD target ($R_{t+1} + \gamma \hat{v} (S_{t+1}, \textbf{w})$) 이다.
- 목표 타겟값에 가중치 $\textbf{w}$ 가 포함되어 있어, 미분식이 기존의 TD Update 식과 다르게 된다.
- The TD Update : $-(U_t - \hat{v}(S_t, \textbf{w})) \nabla \hat{v}(S_t, \textbf{w})$
- 여기에서 TD Update 란 시간차 학습에 의한 실제값과 기대값의 차이를 줄이기 위한 방법을 의미한다.
- 함수 근사에서 사용될 경우 위와같은 형태가 됨.
- 즉, 실제 값과 기대값의 차이가 아닌 기대값과 기대값 사이 TD 오차에 비례하는 위의 식은 gradient descent 방법과는 다르다.
- 위의 차이에도 불구하고, TD 는 많은 케이스에서 수렴한다.

- Semi-Gradient TD(0) 의 psuedocode
- TD(0) 는 에피소드가 끝날 때 까지 기다리지 않고, 매 스텝마다 업데이트를 진행한다.
Comparing TD and Monte Carlo with State Aggregation
- 학습목표
- TD 가 편항된 가치 추정으로 수렴하는 점을 이해
- TD 가 Gradient Monte Carlo 보다 훨씬 빠르게 수렴하는 점을 이해
-
Gradient Monte Carlo 의 경우
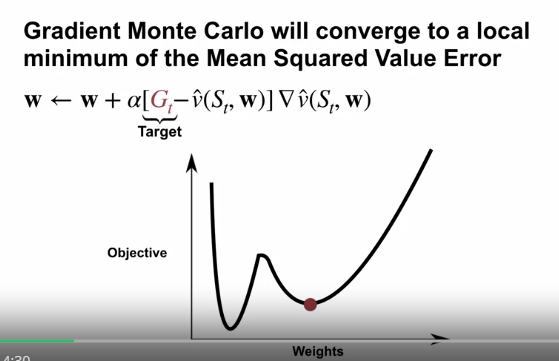
- 더 많은 샘플들로 최적화 할 수록 Mean Squared Value Error 의 지역최소값에 수렴한다.
- 이는 value error의 경사로 편향되지 않은 추정값을 사용하기 때문이다.
- 이론대로라면, 우리는 이 알고리즘을 긴 시간동안, step-size 파라미터를 decay 하며 진행해야 수렴값을 얻을 수 있다.
- 예제에서 상수 step-size 를 사용하여, 지역 최소값에서 계속 진동하는 것을 볼 수 있다.
-
Semi-Gradient TD 의 경우
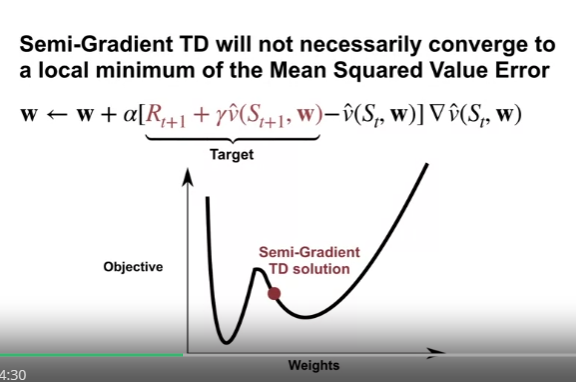
- Target 값이 예측값 (정확하지 않은 값) 이므로, 업데이트 값에 편향이 생길 수 있다.
- 우리의 가치 근사가 경계값 내에서도 완벽할 수 없으므로, Target 은 편향된 상태로 남게 된다.
- 따라서 Semi-Gradient TD 의 Mean Squared Value Error 가 지역 최소값으로 수렴한다는 것을 보장할 수 없다.
- 물론 이 편향은 추정이 개선될 수록 줄게 된다.
-
State Aggregation 을 이용한 1000 State Random Walk 문제에서 MC 방식과 TD 방식의 결과 비교
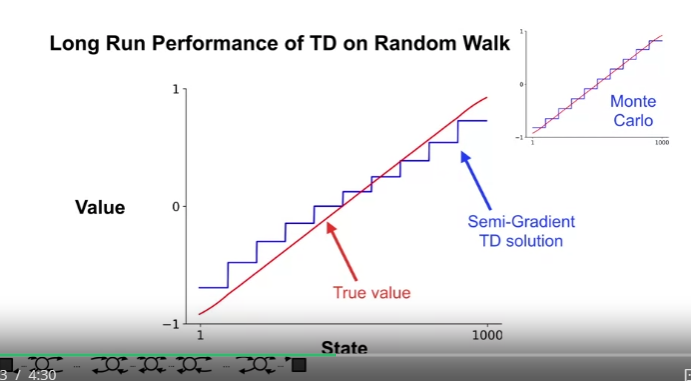
- 1000 State Random Walk 를 값이 수렴할 때까지 진행 (1000 Episodes)
- Value Estimate 값의 변화가 멈추었을 때의 결과를 도식화함.
- Monte Carlo 와 비교하여 값이 정확하지 않다. (편향값 때문)
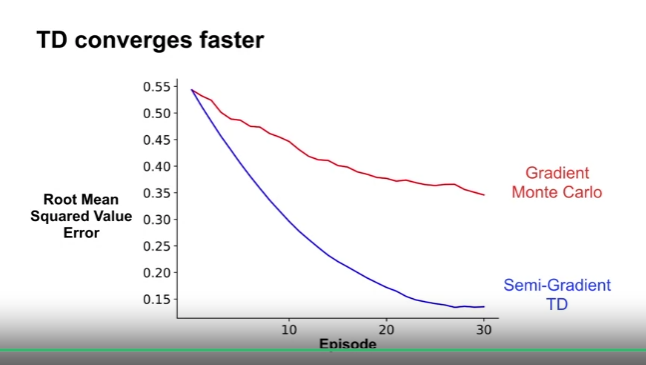
- 위 문제를 30 Episodes 만 진행
- TD 와 MC 의 $\alpha$ 값에 큰 차이가 있으므로, 0과 1 사이의 100개 구간으로 시험하여 가장 좋은 결과의 $\alpha$ 를 선택
- TD : 0.22
- MC : 0.01
Doina Precup : Building Knowledge for AI Agents with Reinforcement Learning
- 강화학습 에이전트가 습득해야 하는 지식의 종류
- 절차적 지식 (일을 수행하는 방법) - 정책은 이에 해당하는 기본적인 예
- 우리가 알고 싶어할 수도 있는 다른 지식 - 특정 물체와 상호작용하는 방법, 다른 장소로 이동하는 방법
- 기술, 옵션, 혹은 목표 지향적인 행동
- 에이전트의 행동에 따라 어떤 일이 일어날 수 있는지를 의미하는 예측 지식, 경험적 지식
- 이것은 가치 함수일 뿐만 아니라 모델 예시와 같은 다른 것이기도 하다.
- 이러한 종류의 지식에 대해 우리가 갖고 싶은 특정 특성
- 배울만한 지식을 알게 되어, 데이터로부터 그것을 얻고, 표현할 수 있기를 원함
- 에이전트가 다양한 것, 다양한 상황에 대해 알수 있기를 원하며 이미 가지고 있는 지식 조각을 더 큰 조각으로 구성할 수 있기를 바람
- 지식 표현의 요소
- 타임 스케일에 따른 에이전트의 행동 측면에서의 일반화
- 세상에 대해 인식, 추론하는 에이전트의 능력에서의 일반화
- 상태 추상화와 함수 근사 (위의 필요성에서 등장)
- 다른 타임 스케일에서의 절차적 지식의 일반화
- 에이전트가 생성될 때, 할 수 있는 행동은 제한적이고 이러한 행동들은 항상 한 번의 time step 동안 지속된다.
- 이는 MDP (Markov Decision Process) 프레임워크와 일치시키기 위한 것이다.
- 강화학습에서 상태, 행동, 보상 등은 시간 단게에 따라 발생하며 에이전트가 처음 생성될 때 행동의 다양성이나 지속 시간 등이 제한될 수 있다.
- 다른 타임 스케일에서의 절차적 지식의 일반화
- 에이전트의 행동의 기간을 단일 단계가 아닌 여러 단계로 확장하는 방법
- 옵션이라는 개념의 사용
- 초기화 단계 : 옵션이 시작될 수 있는 조건
- 내부 정책 단계 : 옵션 실행 중 취할 행동
- 종료 단계 : 언제 종료되는지 결정하는 조건
- 옵션이라는 개념의 사용
- 추상화의 개념으로 본 옵션
- MDP : 에이전트가 단일 행동에 대한 보상과 상태 전이에 대한 정보를 가지고 있음
- 옵션 : 일련의 행동들에 대한 일종의 전략이며 각 행동마다 보상과 상태 전이 확률을 내재하고 있는 개념 (행동의 집합, 패턴)
- 시간의 추상화 : 옵션이 언제 시작되고 언제 종료되는지는 가변적이다. 또한 이를 통해 고정된 time step 에서 벗어나게 된다. (Semi-MDP)
- 상태의 추상화 : 구체적인 좌표값이 아닌 공항에 대한 추론을 한다.
- 행동의 추상화 : 각 근육의 조절이 아닌 공항으로 가는 행동에 대해 생각한다.
- 이는 MDP에서의 행동보다는 더 큰 시간적, 행동적, 그리고 상태적인 추상화 수준을 제공한다.
- 위의 추상 항목들은 모두 별개이며 함께 잘 작동하도록 조율하는 방법은 연구가 필요한 문제이다.
- 옵션을 학습하는 강화학습 방법
- 어떤 옵션을 사용할지 또한 선택이며, 이 또한 학습의 대상이다.
- 옵션을 학습하는 강화학습 방법 중 하나, “Option-Critic Architecture”
- 옵션 선택기 (Option Selector): 에이전트가 주어진 상태에서 어떤 옵션을 선택할지 결정하는 부분. 이 선택기는 가능한 옵션들의 가치를 추정하여 가치가 높은 옵션을 선택하도록 학습됨
- 옵션 평가자 (Option Evaluator): 선택된 옵션이 얼마나 좋은지, 즉 해당 옵션의 예상 보상이 어떤지를 평가하는 부분. 이 평가자는 선택된 옵션의 가치를 추정하고, 이를 통해 선택된 옵션이 잘 수행될 것인지를 예측함.
- 이 아키텍처를 통해 옵션 선택과 평가를 결합하여 옵션을 효과적으로 학습하고 발전시킬 수 있다. 이러한 접근 방식은 여러 상황에서의 옵션 선택과 실행에 대한 전략을 효과적으로 학습하고 조정할 수 있도록 돕는다.
Linear TD
The Linear TD Update
- 학습목표
- 선형 함수 근사 를 사용하여 TD-update 도출
- tabular TD(0) 가 linear semi-gradient TD(0) 의 특별한 케이스인 것을 이해하기
- 왜 linear TD 를 특수 케이스로 취급하는지 이해하기
-
TD Update with Linear Function Approximation

- 가중치를 해당 가중치에 해당하는 TD error 와 근사가치함수의 경사값의 곱의 값에 따라 조절한다.
- 이 때, 근사가치함수의 경사값은 선형 가치근사함수에 의해 feature vector 의 값이 된다.
- feature 값이 크면 큰 영향을 주게 되고, feature 값이 0이면, 아무런 영향을 주지 않는다.
- 즉 선형가치근사함수의 경우 feature 값이 잘 선택되면 효율적으로 작동한다.
-
Tabular TD is a special case of linear TD

- 위의 식과 같이 모든 상태에 대해 각각의 대응하는 가중치값이 존재한다면, 이는 tabular td 와 동일한 형태가 된다.
- 선형함수근사의 유용성
- 선형 방식은 이해하기 쉽고 수학적으로 분석이 가능하다.
- 좋은 feature 가 있으면 선형 방식은 학습도 빠르고 좋은 예측 정확도를 보여줄 수 있다.
The True Objective for TD
- 학습목표
- linear TD 학습의 고정점 (fixed point) 에 대해 이해
- TD 고정점에서 평균 제곱 오차의 이론적 보증에 대한 설명
-
The Expected TD Update

- 위 Expected TD Update 식은 아래의 연산규칙에 의해 변형이 가능하다.
- 위 식에 사칙연산 중 분배법칙이 성립한다.
- 스칼라 값 (벡터간 내적곱) 은 전치해도 식이 변형되지 않는다.
- 위의 규칙에 의해 변형된 식에 대해서
- Matrix A : feature 에 대한 기대값
- vector b : feature 와 보상에 대한 항
- 위 Expected TD Update 식은 아래의 연산규칙에 의해 변형이 가능하다.
-
The TD Fixed Point
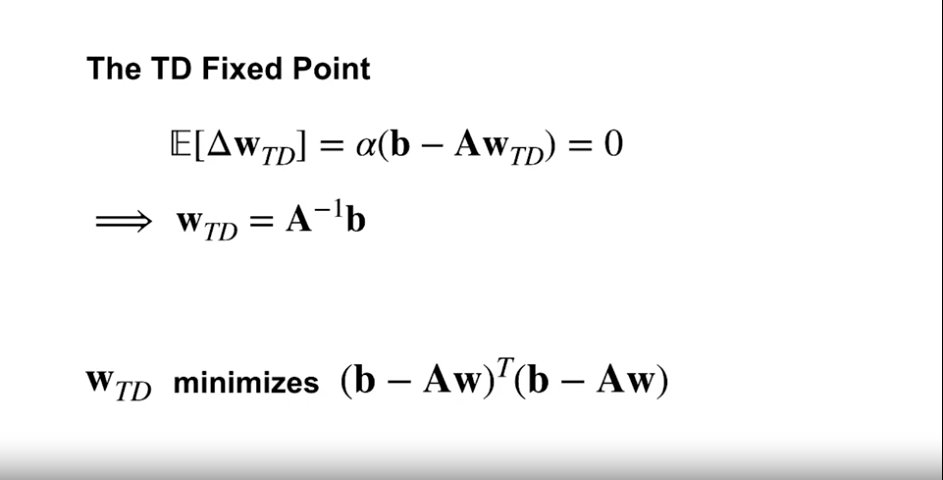
- TD 업데이트가 선형인 경우
- 테이블 설정에서 벨만 방정식을 해결하는 것이 아닌 (샘플데이터 사용)
- 해(solution)를 수식으로 구하는 방식인 선형 TD에 대해 설명하고 있음.
- 선형 TD는 TD 업데이트를 선형 함수로 근사하며, 이를 사용하여 벨만 방정식의 해를 직접 구한다.
- 여기서 해(solution)는 TD 고정점(TD fixed point)을 의미한다.
- 이 해는 평균 제곱 오차(Mean Squared Value Error)의 최소값으로 수렴하지는 않지만
- TD의 목적 함수에 기반한 원칙적인 최소값으로 수렴한다는 것을 설명하고 있다.
- 따라서 TD의 학습 목표는 평균 제곱 오차의 최소값이 아닌, 벨만 방정식과 관련된 목적 함수의 최소값을 찾는 것이 된다.
- TD 업데이트가 선형인 경우
-
TD Fixed Point 와 Minimum of the Value Error 의 관계

- 그럼에도 불구하고, 우리는 여전히 TD에 의해 찾아진 해와 오류를 최소 값으로 만드는 해 사이의 관계를 알고 싶음.
- 위 방정식과 같이 $\gamma$ 가 0에 매우 가깝다면, TD Fixed Point 는 Minimum of the Value Error 의 해와 매우 가까워짐
- Feature 의 품질과도 연관이 있는데, Feature 가 제한적이라면 TD Fixed Point 나 Minimum of the Value Error 또한 커지게 됨.
- 만약 가치함수를 완벽하게 나타낼 수 있다면, $\gamma$ 와 무관하게 TD Fixed Point 는 Minimum of the Value Error 와 동일하게 됨.
- 양쪽 모두가 0 가 되기 때문
- TD Fixed Point 와 Minimum of the Value Error 의 해와 차이가 발생하는 이유
- 함수 근사값의 부트스트래핑 목표를 사용하기 때문
- 다음 상태에 대한 추정이 함수 근사로 인해 지속적으로 부정확하다면, 부정확한 대상을 향해 업데이트 됨.
- 만약 함수 근사가 좋다면 다음 상태에 추정값은 매우 정확해짐.
- 그럼에도 불구하고, 우리는 여전히 TD에 의해 찾아진 해와 오류를 최소 값으로 만드는 해 사이의 관계를 알고 싶음.
댓글남기기